In one of the previous articles, we have started with a case study example from the telecom sector. We learned about cluster analysis using black holes as an analogy. In that article, we used Euclidean distance to form customer segments. Let us continue with the same case study and learn about Euclid. Additionally, we will also learn about the usefulness of data normalization to avoid spurious results while performing cluster analysis through Euclidean distance.

Euclid – by Roopam
Euclid
In 1440 Johannes Gutenberg invented the printing press, a device that changed the course of human history by providing an affordable source of information to the masses. One of the earliest texts to be published through this great invention was Euclid’s ‘Elements’, published in 1482 in Venice. ‘Elements’ is one of the most published books in the history of mankind next only to the Bible. ‘Elements’ consists of 13 books that cover propositions in geometry. All the geometric theorems in ‘Elements’ can be derived from 10 axioms or postulates. For instance, one of the famous axioms presented in ‘Elements’ is – one can only draw one straight line between two points. If one has to find a man who is known only for his work, Euclid of Alexandria is certainly a great candidate. Very little is known about Euclid as a person and he is often referred to as the “Father of Geometry”. It is estimated that he lived in 300 BC and taught at Alexandria in Egypt during the reign of Ptolemy I. This is all we know of Euclid, the author of one of the most influential books of all times.
On the Shoulders of Giants
Isaac Newton once honored his predecessors for his contribution to physics with the following quote “If I have seen further it is by standing on the shoulders of giants”. Development of human knowledge is a collective activity. Similarly Euclid’s ‘Elements’ is a culmination of ideas and propositions from several mathematicians and a few original ideas of its author. However, as was a common practice in those days, Euclid did not give credit to several mathematicians while using their work. Pythagoras must be one of the giants on whose shoulders Euclid stood and saw further. We will use the Pythagoras theorem in the next segment to derive Euclidean distance. This will also help us understand the usefulness of data normalization in cluster analysis.
 Euclidean Distance
Euclidean Distance

Recall, in the same article I mentioned above on customer segmentation and cluster analysis, we have estimated the cluster centroid using Euclidean distance. Let us try to derive the Euclidean distance formula using the famous Pythagoras theorem. We have all learned Pythagoras theorem in primary school. The simple property about right triangles makes the square of the hypotenuse (z) equal to the sum of the squares of the remaining two sides (x and y). Mathematically represented as
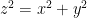
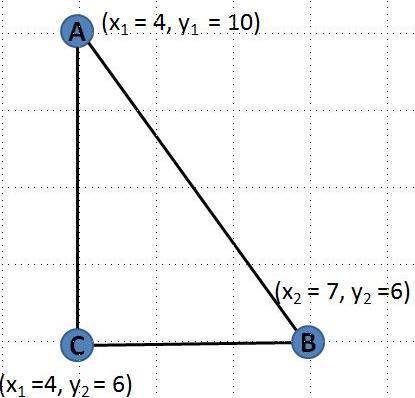 Now, let us make an attempt to find the distance between two points (A & B) in the two-dimensional plane (x & y-axis). The positions of the first point are 4 on the x-axis and 10 on the y this can also be written as (4,10). Similarly, the position of the second point is (7,6) as shown in the above diagram.
Now, let us make an attempt to find the distance between two points (A & B) in the two-dimensional plane (x & y-axis). The positions of the first point are 4 on the x-axis and 10 on the y this can also be written as (4,10). Similarly, the position of the second point is (7,6) as shown in the above diagram.
Now to measure the distance between these two points, let us create a right triangle as shown in the adjacent diagram. Notice that the coordinates for the point C (4, 6) is taken from x coordinate of A and y coordinate of B. Now the length of the line AC is y1-y2 i.e. (10-6 = 4) since the x coordinate is fixed on this line. Similarly, the length of the line BC is x2-x1 i.e. (7-4 =3). Finally, using Pythagoras theorem we can find the value of length of the line AB i.e.

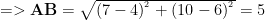
The shortest distance between two points is the length of the unique line drawn between them. Hence the shortest distance between two points A and B is 5.
Telecom case study Example – Cluster Analysis
 Keeping the above in mind, let us come back to the telecom case study. This time as the head of customer insights and marketing at a telecom company, ConnectFast Inc, you want to perform cluster analysis for customer segmentation using two variables: age and income. There are two customers with the following ages 37 years and 44 years and their annual income are $90,000 and $62,000. Now if you have to find the Euclidean distance between (37, 90000) and (44, 62000), we will form a right triangle similar to the one shown adjacent. Note, this plot is not drawn according to scale otherwise, it will show just a straight line.
Keeping the above in mind, let us come back to the telecom case study. This time as the head of customer insights and marketing at a telecom company, ConnectFast Inc, you want to perform cluster analysis for customer segmentation using two variables: age and income. There are two customers with the following ages 37 years and 44 years and their annual income are $90,000 and $62,000. Now if you have to find the Euclidean distance between (37, 90000) and (44, 62000), we will form a right triangle similar to the one shown adjacent. Note, this plot is not drawn according to scale otherwise, it will show just a straight line.
In this case, it is easy to notice that the income variable is dominating the distance by a large margin of 28000 to 7. This is certainly a highly skewed picture. We need to think of a strategy to counter this problem otherwise our cluster analysis will give spurious results. The strategy will involve bringing both the variables on comparable scales. Data normalization presents a solution to our problem.
Data Normalization
There are various ways of data normalization. The one we are going to use here is called min-max normalization. The normalization is performed using the following formula

Here,
X* is the normalized value of the variable
min(X) is the minimum value in the dataset for the variable
max(X) is the maximum value in the dataset for the variable
Now for our example, let us assume in our base of customers we have the maximum income of $130000 and the minimum income of $45000. The normalized value of income for the customer A is

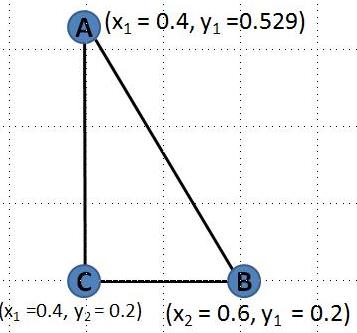
We will perform the same exercise for all the data points for all the variables. The income for the second customer i.e. 62000 will become 0.2 after performing the same normalization. Additionally, the minimum and maximum age of customer base are 23 and 58 years. This will make normalized ages of two customers equal to 0.4 and 0.6.
In this case, it is easy to see that all the normalized value will fall between the range of 0 and 1. Hence we have created a normalized data set that is on a comparable scale. The normalized plot, as shown adjacent, is not as skewed as the original plot. We have rectified the problem.
It is always advisable to perform normalization before cluster analysis since most data sets suffer from the problem described above.
Sign-off Note
I have started measuring the Euclidean distance between the frequency of posting of articles on YOU CANalytics. Of late there is a little variation in the posting of articles because of my busy schedule. I prefer to post an article every week or fortnight and would like to stick to this schedule. However, as a statistician, I know that every data set has a variation and I cannot avoid the variation in time of posting the articles on the site. I also know, as a reader you are extremely forgiving and won’t mind a little bit of variation. See you soon with the next post!
Hi Roopam,
Firstly, I would like to appreciate your efforts for sharing your experiences from industry that are really conducive to the learning of newbie like me.
In the above section you talked about the data normalization and mentioned that there are several other techniques to bring all the variables to same scale. I know of calculating the Z-values and use them in the clustering. Though i believe that both Normalization and Standardization will serve the purpose, i am curious to know are there any specific scenarios where we have to make choice between these two.
Regards
Apoorv
Thanks Apoorv, This reply is delayed by a long time – sorry for that. I just missed your comment. I don’t think choice of either normalization or standardization will much of a difference for a well distributed data. The range for min-max normalization is (0,1), and Z-scores varies mostly around (-2,2). Z-score is better in terms of outliers detection.