In the last post we had started a case study example for regression analysis to help an investment firm make money through property price arbitrage (read part 1 : regression case study example). This is an interactive case study example and required your help to move forward. These are some of your observations from exploratory analysis that you shared in the comments of the last part (download the data here)
Katya Chomakova : The house prices are approximately normally distributed. All values except the three outliers lie between 1492000 and 10515000. Among all numeric variables, house prices are most highly correlated with Carpet (0.9) and Builtup(0.75).
Mani : Initially, it appears as if housing price has good correlation with built up and carpet. But, once we remove all observations having missing values (which is just ~4% of total obs), I find that the correlation drops down very low (~0.09 range)

Data Preparation for Regression Analysis – by Roopam
Katya and Mani noticed something unusual about missing observations and outliers in the data, and how their presence and absence were changing the results dramatically. This is the reason data preparation is an important exercise for any machine learning or statistical analysis to get consistent results. We will learn about data preparation for regression analysis in this part of the case study. Before we explore this in detail, let’s take a slight detour to understand the crux of stability and talk about fall of heroes.
Every kid needs a hero. I had many when I was growing up. This is a story of how I used a concept in physics caller ‘center of gravity‘ to chose one of my heroes by having an imaginary competition between:
Mike Tyson Vs. Bop Bag
The Champion : Mike Tyson was the undisputed heavyweight boxing champion in the late 1980s. He was no Mohammad Ali but was on his path to come closest to The Greatest. This is where things went wrong for Tyson; he was convicted of rape and was in prison for 3 years. Out of jail and desperate to regain his glory days, Tyson challenged Evander Holyfield,the then undisputed champion. What followed was a disgrace for any sport where during the challenge match Tyson bit a part of Holyfield’s ear off and got disqualified.
The Challenger : Most of us have played with a bop bag or the punching toy as kids. It is designed in such a way that when punched, it topples for a while but eventually stands back up on its own. Bop bag is a perfect example where the center of gravity of the object is highly grounded and stays within its body. You could punch it, kick it, or perturb it in any possible way but the bop bag will stand back up after a fall – yes, it has that cute, funny smile too. On the other hand, like Mike Tyson, most of us struggle big time after a fall. Possibly because our center of gravity is outside our body in other people’s opinion about us. Tyson was mostly driven by the praises from others after a win rather than his love for the game.
The Winner : Center of gravity helped me choose my hero : bop bag. This cute toy reminds me every day to keep my center grounded and inside my body and not let others perturb my core – even when punched. I wish I could always wear a sincere smile like my hero.
Bop bag also has important lessons for data preparation for machine learning and data science models. The data for modeling needs to display stability similar to bop bag and must not give completely different results with different observations. Katya and Mani have noticed a major instability in our data in their exploratory analysis. They have highlighted the presence of missing data and outliers; we will explore these ideas further in this part when we will explore data preparation for regression analysis. Now, let’s go back to our case study example.
Data Preparation for Regression – Case Study Example
 You are a data science consultant for an investment firm that tries to make money through property price arbitrage. They get daily data for thousands of houses across the country available for sale. Their expectation from you is to suggest properties worth investing in. This requires you to identify properties selling at a lower price than the market price. You already have quoted prices for all the properties. Now, you need to create a model to estimate market price for properties. Your client should invest in the properties with a higher estimated price than the quoted price.
You are a data science consultant for an investment firm that tries to make money through property price arbitrage. They get daily data for thousands of houses across the country available for sale. Their expectation from you is to suggest properties worth investing in. This requires you to identify properties selling at a lower price than the market price. You already have quoted prices for all the properties. Now, you need to create a model to estimate market price for properties. Your client should invest in the properties with a higher estimated price than the quoted price.
In your effort to create a price estimation model, you have gathered this data. The next step is data preparation for regression analysis before the development of a model. This will require us to prepare a robust and logically correct data for analysis.
We will do our analysis for this case study example on R. For this I recommend you install R & R Studio on your system. However, you could also try these codes on this online R engine : R-Fiddle.
We will first import the data in R and then prepare a summary report for all the variables using this command:
data<-read.csv('http://ucanalytics.com/blogs/wp-content/uploads/2016/07/Regression-Analysis-Data.csv') summary(data)
A version of the summary report is displayed here. Remember there are total 932 observations is this data set.
| Dist_Taxi | Dist_Market | Dist_Hospital | Carpet | Builtup | |
| Min. | 146 | 1666 | 3227 | 775 | 932 |
| 1st Qu. | 6476 | 9354 | 11302 | 1318 | 1583 |
| Median | 8230 | 11161 | 13163 | 1480 | 1774 |
| Mean | 8230 | 11019 | 13072 | 1512 | 1795 |
| 3rd Qu. | 9937 | 12670 | 14817 | 1655 | 1982 |
| Max. | 20662 | 20945 | 23294 | 24300 | 12730 |
| NA’s | 13 | 13 | 1 | 8 | 15 |
Look at the last row where all the above variables have some missing data. Parking and City_Category are categorical variables hence we have got levels for them. Notice there is missing data in Parking as well marked as ‘Not Provided’.
| Parking | City_Category | Rainfall | House_Price | |
| Covered : 188
No Parking: 145 Not Provided : 227 Open : 372 |
CAT A: 329
CAT B: 365 CAT C: 238
|
Min. | 110 | 30000 |
| 1st Qu. | 600 | 4658000 | ||
| Median | 780 | 5866000 | ||
| Mean | 785.6 | 6084695 | ||
| 3 Qu. | 970 | 7187250 | ||
| Max. | 1560 | 150000000 | ||
| NA’s | 0 | 0 |
The first thing we will do is to remove missing variables from this dataset. We will explore later whether removal of missing variables is a good strategy or not. We will also calculate how many observations we will lose by removing missing data.
data_without_missing<-data[complete.cases(data),]
nrow(data) - nrow(data_without_missing)
We have lost 34 observations after removal of missing data. The data set is now down to 898 observations. This is ~4% observations as Mani pointed in his comment. Also, notice that missing variables for categorical variables (Parking) are not removed, could you reason why?
In the next step, we will plot a box plot of housing price to identify outliers for the dependent variable.
options(scipen = 100) # this will print the numbers without scientific notation boxplot(data_without_missing$House_Price, col = "Orange",main="Box Plot of House Price")
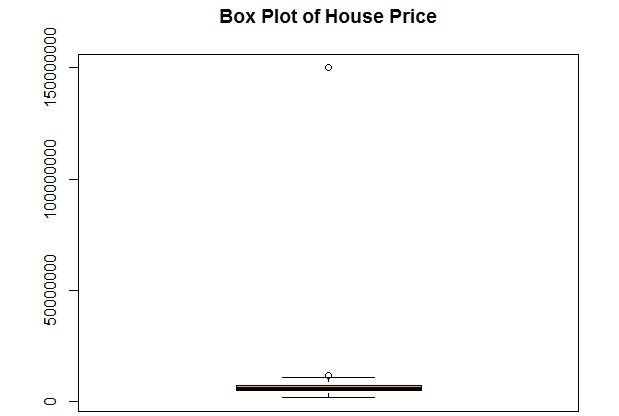 Clearly, there is an extreme outlier in this dataset. The dot at the top represents that outlier. All the other data-points are packed in the almost flat box at the bottom. (Click on the image to enlarge it)
Clearly, there is an extreme outlier in this dataset. The dot at the top represents that outlier. All the other data-points are packed in the almost flat box at the bottom. (Click on the image to enlarge it)
Let’s try to look at this extreme outlier by fetching this observation.
data_without_missing[data_without_missing$House_Price>10^8,]
This observation seems to be for a large mansion in some countryside. As can be seen in data when compared with the summary data for other observations.
| Dist_Taxi | Dist_Market | Dist_Hospital | Carpet | Builtup | Parking | City_Category | Rainfall | House_Price |
| 20662 | 20945 | 23294 | 24300 | 12730 | Covered | CAT B | 1130 | 150000000 |
There is no point in keeping this super-rich property in data while preparing a model for middle-class housing. Hence we will remove this observation. The next step is to look at the box plot of all the numerical variables in the model to find unusual observations. We will normalize the data to bring it to the same scale.
boxplot(scale(data_without_missing[data_without_missing$House_Price<10^8,c(2:6,9:10)]),col="Orange")
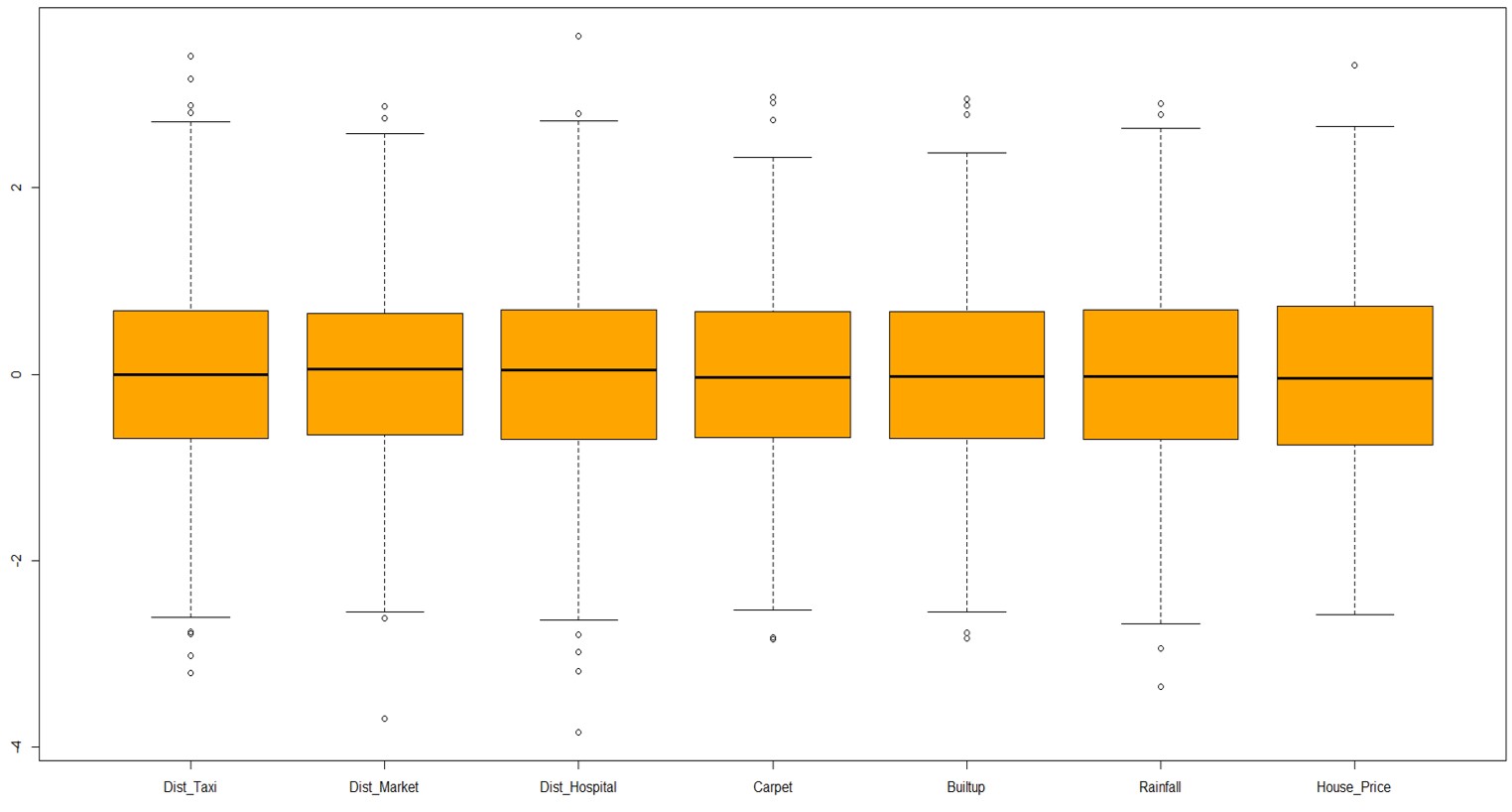 This data looks fairly centered as is required for most modeling techniques.
This data looks fairly centered as is required for most modeling techniques.
Sign-off Note
In this part, we have primarily spent our time on univariate analysis for data preparation for regression. In the next part, we will explore patterns through bivariate analysis before the development of multivariate models. These are some of the questions you may want to ponder and share your view before the next part:
1) We had removed 34 observations with missing data, what impact the removal of missing data can have on our analysis? Could we do something to minimize this impact?
2) Why did we not remove missing values from the categorical variable i.e. Parking?
3) What impact could the extreme outlier, a large mansion, have on the model we are developing for middle-class house prices? Was it a good idea to remove that outlier?
In my opinion it is not always a good idea to exclude missing values from our data for several reasons:
1. We can lose a great amount of data, which is not our case here but is still an issue.Losing data is considered an issue because the amount of data that we use for modeling is crucial for the statistical significance of our results.
2. Sometimes the fact that a value is missing carries a message. For example, missing value for Dist_Hospital could mean that there is no hospital nearby. The same is true for Dist_Taxi and so on. When this is the case, we can impute values to missing data that represent the underlying reason for the data to be missing. For example, missing values for Dist_Hospital might be replaced with a huge number meaning that there is no hospital in the near distance.
3. When we can’t consider the reason behind missing values but we still don’t want to exclude them, a reasonable approach is to impute to missing values the average value for the corresponding variable.
According to outliers, we should first examine if they are also high leverage points. If this is the case these observations have a potential to exert an influence to our model and it is recommended to exclude them. If they are not high leverage points, whether to exclude them depends on the modeling technique we would like to use. Decision trees are more sensitive to outliers than regression models.
I am looking forward to your next post on the topic.
I do agree with Katya. Here is my opinion about 1.missing values and 2.outliers:
1. Missing values can cause serious problems. Most statistical procedures automatically eliminate cases with missing values, so you may not have enough data to perform the statistical analysis. Alternatively, although the analysis might run, the results may not be statistically significant because of the small amount of input data. Missing values can also cause misleading results by introducing bias.
2. Values may not be identically distributed because of the presence of outliers. Outliers are inconsistent values in the data. Outliers may have a strong influence over the fitted slope and intercept, giving a poor fit to the bulk of the data points. Outliers tend to increase the estimate of residual variance, lowering the chance of rejecting the null hypothesis.
Hi Roopam,
Below is my opinion on the three points:-
1) Instead of removing the missing Data, can’t we substitue some value like taking avg of other observations of that column,etc. I am suggesting this because we might lose some important information by directly removing the missiong value observations.
2) flats having no parking availability can leads to useful information like a middle class family does not require parking space and they may buy flat with no parking facility. I am not quite so sure about this point. Kindly correct me if i am wrong.
3) outliers can lead to our observation in wrong side. But sometimes it is useful to identify some hidden patterns in our data. In our case, this extreme outlier can do a bad impact in our analysis as we are more focused for middle class house prices. so in my opinion, its a good idea to remove it.
1) We had removed 34 observations with missing data, what impact the removal of missing data can have on our analysis? Could we do something to minimize this impact?
Reply – Missing data can bias the model especially when we have Missing values at random and missing values not at random. We can use little test to confirm if the Missing is completely at random. If yes, we can go ahead with the list wise deletion. If it is missing at random we can use multiple imputation methods to use other variables to impute the values and build models on the complete data sets.
3) What impact could the extreme outlier, a large mansion, have on the model we are developing for middle-class house prices? Was it a good idea to remove that outlier?
Reply – This extreme outlier can highly influence the model parameters. Checking Cook distance and h(leverage of an observation) indicates the observation is a high leverage and point and, therefore, we should remove it before training our model.
Hi Roopam,
If i am not wrong, scale fn works like (x-mean)/sd , so when do we use this scaling process and when do we use log transformation for normalization ? is there any rule ?
Scaling and log transformation have completely different purposes and they cannot be used interchangeably. One of the usage of Scale is in cluster analysis (Read this article) where you are trying to bring different variables on the same scale. On the other hand, log transform is used to make a screwed distribution normal e.g. ARIMA and time series models
Thanks 🙂 it’s a great help 🙂
boxplot(scale(data_without_missing[data_without_missing$House_Price<10^8,c(2:6,9:10)]),col="Orange")
Throwing this error
Error in `[.data.frame`(data_without_missing, data_without_missing$House_Price < :
undefined columns selected
boxplot(scale(data_without_missing[data_without_missing$House_Price<10^8,c(2:6,9:10)]),col="Orange") need python code