Facebook was a major sensation and a source of great amusement in a British country house in the early 20th century. It was such a big hit that it got a special mention in a newspaper published in the year 1902. Facebook, then, of course, had a completely different meaning than the online social media we know.

The Western Times cutting from 1902 Source: www.irishmirror.ie
A lot of human knowledge and amusing facts, like this newspaper cutting, still exist in non-digital formats. The job of converting such documents to digital text format, like MS word doc, is performed by optical character recognition (OCR) tools. Notably, such machine-encoded-text is much easier to classify, search, modify, store, and analyze. An OCR conversion of the same cutting is displayed here.
Most OCR tools do a good job but they still make mistakes as we saw for our newspaper cutting. Here, nobody cares about ‘lenee-book’ (as this OCR tool deciphered ‘Face-book’). This tool, notably, got 49 out of 52 words correctly. This was not an easy task even for our eye on this more than a century-old cutting. In terms of individual characters, we have got 98.3% accuracy here with just 5 mistakes out of 288 characters.
OCR is also a source of excitement for data scientists since, using OCRs you could use non-digital data, such as application forms, electricity bills, receipts, etc., for your analysis.
Deep Learning Models and OCR
Almost all OCR software tools in the market are powered by deep learning models. In this article, we will learn how deep learning converts a newspaper cutting to a word document. This is similar to how your eyes see a book and convert the ink marks into the familiar characters in your brain. Yes, we are entering the realm of artificial intelligence.
In this and the subsequent article, you will build models, and learn how to improve the accuracy of an OCR using machine learning (ML) and deep learning models. You will build four models with these accuracies on the test data.
- Logistic regression (Model 1): 92% accuracy
- Random forest (Model 2): 96.8% accuracy
- Deep learning neural networks (Model 3): 97.9% accuracy
- Convolution neural networks (Model 4): 99.1% accuracy
Keep an eye for what is going behind the scenes for the error to reduce over 85% from logistic regression to CNN. But before we start, let’s meet Popeye and see how he is similar to machine learning and deep learning models.

Popeye and Deep Learning Models – by Roopam
Data for Machine Learning & Deep Learning Models
Popeye the sailor’s love-interest Olive Oyl is kidnapped by his arch-rival Bluto. He is no match for Bluto’s strength but Popeye has to save Olive Oyl. Popeye gobbles down a can of spinach and gains superhuman-strength to beat Bluto the brute. Our hero is triumphant again! Popeye gets all his strength from spinach and nothing else. If he eats potatoes or tomatoes or anything else he will continue to be inferior to Bluto. Machine learning or deep learning models are no different.
Deep learning models are powered by the way they gobble data. The data have to be in a specific format (like spinach) for ML and DL models to learn from them. Let’s try to understand this using this picture. We see the number ‘2’ in this 2-dimensional image or 2D pixelated data. ML and DL models can’t digest 2D or higher dimension data. They get their strength, like just spinach, from the 1D data (a vector) displayed in the image.
![]()
This is a black-and-white image hence has just 2-dimensions (2D). A color image with red-green-blue (RGB) components is a 3D data. A color video is 4-dimensional with an additional time dimension. This higher dimension data is transformed to 1D for ML algorithms to digest them. OK, so now that you are aware of this important requirement, you are ready to start your…
Machine Learning and Deep Learning Models
 You can find the Python notebook with the entire code used in this article here: YOU CANalytics – Machine Learning & Deep Learning Models. The first thing to build an OCR is to get image data from an enormous number of newspaper articles (like we saw earlier). The next task is for humans to read these articles and convert them to a digital format on a Notepad application. Machines will then learn using both the original articles and the digital format. When machines have seen enough such data and learned from them, they will be able to read an unknown document and convert it to the digital format.
You can find the Python notebook with the entire code used in this article here: YOU CANalytics – Machine Learning & Deep Learning Models. The first thing to build an OCR is to get image data from an enormous number of newspaper articles (like we saw earlier). The next task is for humans to read these articles and convert them to a digital format on a Notepad application. Machines will then learn using both the original articles and the digital format. When machines have seen enough such data and learned from them, they will be able to read an unknown document and convert it to the digital format.
The process is exactly the same for hand-written text as well. Someone has done this hard job of converting images of many hand-written digits, as shown below, to digital format (0,1,..,9). Here, you are seeing 50 different images from the same large image dataset of 70,000 images. These images and corresponding digits are part of a popular and freely available dataset called MNIST.

These are all 28×28 pixel images. Now, the machine learning algorithm knows that the first five images are of the digit ‘0’ and the next five are ‘1’s and so on. We will make the algorithm learn or train using any 60,000 of these 70,000 images. The remaining 10,000 images will then be the test set or unknown images for the algorithm. If the algorithm does a good job on the unknown test set then we have our first OCR application for hand-written numbers or digits.
Data Preparation for Machine Learning & Deep Learning Models
An image is nothing but a matrix of numbers as displayed here. Here, 255 displays the most intense shade (black here) and 0 displays absence of that shade (i.e white in this case). Similarly, greys will be some numbers between these extremes.

Now, we can easily transform this matrix to flatten it to a single row with X1 to X15 as predictor variables and Y as the target. Y is tagged by humans after looking at the image. We will have 60,000 such rows with 28×28 = 784 predictor variables for our data. Now let’s use this data to build our first logistic regression model.
Model 1: Logistic Regression
We have discussed logistic regression in great detail in YOU CANalytics earlier. Check out those articles. In this case, since the target variable has 10 categories (digits: 0,1,..,9), we will build 10 different logistic regression models to predict the probability of an image being any of these 10 digits. A single logistic regression model predicts the probability of one digit against the remaining nine digits.
Here, you can see the output of the logistic regression model for one of the test images.

Logistic regression predicts 97.8% probability of this image being ‘0’. The models did a good job for this image. However, the logistic regression models made mistakes for close to 800 test-images out of 10,000 with 92% accuracy. Here you see one such image with the wrong output. (image # 38 in the test set.)

Here, logistic regression is classifying this image as either 2, 3, or 8 with the same probability (33%). We can all easily see that this is ‘2’. You may also want to see other places where the model has made mistakes. This will be an interesting and enlightening exercise for you. Use this Python script to identify places where the model and humans don’t agree.
import numpy as np import matplotlib.pyplot as plt np.where((Number_test!=Number_pred_LR)) # Change the number in paranthesis [38] to other numbers with mismatches plt.imshow(Image_test[38].reshape(28,28), cmap = matplotlib.cm.binary) classifier.predict_proba(Image_test[38].reshape(1,-1))
The next model we will build using random forest classifiers will correct some of these mistakes.
Model 2 – Random Forest Model

Random forest is a class of machine learning models that builds several decision trees from the same data. Decision trees, for a random forest, are built on randomly selected data from the training data. Notably, this makes the random forest equivalent to a democratic political system where every decision tree has a vote and voice. Read these articles to learn more about decision trees:
Random forest is also a relatively transparent model which explicitly highlights the important features or input variables. This enables us to ask questions such as, where do your eyes focus when they look at the MNIST images to decipher the digits hidden in them? Incidentally, the random forest model gives a good approximation for the same in this feature importance heat map. As expected, your eyes largely ignore the white spaces in the images and so does the random forest model (shown as cold ‘dark blue’ in the heat map). The areas or pixels that are lit-up i.e yellow, green and light blue, are the areas of important features or places where your eyes focus. Random forest model improved the test set accuracy to close to 97%. This model has also correctly classified the image of ‘2’ mistaken by the logistic regression models.
Around 97% seemed like the limit for the test set accuracy for this MNIST dataset before deep learning and neural networks came to the rescue. Notably, an elaborated and well-tuned deep learning model can improve the accuracy to ~99.5%. This is a whopping 83% reduction in the error over the other popular machine learning models. Let’s enter the territories of deep learning models with…
Model 3 – Deep Learning Neural Networks
Recall, we solved this neural network in the last part to understand the math of deep learning. In this network, we had nine parameters to solve i.e. six weights (W1, W2,.., W6) and three bias terms (b1, b2, and b3).
The network we will use for the images of hand-written digits is displayed below. This much more complicated network will require us to solve for 669,706 parameters. This network, first of all, has 784 input variables from 28×28 pixel images. This network has 2 hidden layers with 512 nodes per hidden layers. Finally, there are 10 possible outputs (0,1,..,9). These outputs are then converted to probabilities using the softmax function in the last layer.

Let’s do a quick calculation to understand where these 669,706 parameters are coming from. There are 784 input nodes connected to 512 nodes in the first hidden layer. Additionally, the first bias term is connected to the same 512 nodes in the first hidden layer. This makes the total connections (or parameters to calculate) between the input layer and first hidden layers equal to:
784 × 512 + 512 = 401,408 + 512 = 401,920
Similarly, the first and the second hidden layers are connected by
512 × 512 + 512 = 262,656
Finally, 10 output nodes are connected to 512 nodes the in the second hidden layer and one bias node.
512 × 10 + 10 = 5130
You will get the same information from the summary function of the network in Python / Keras, as displayed here.
nn_mnist.summary()
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_1 (Dense) (None, 512) 401920 _________________________________________________________________ dense_2 (Dense) (None, 512) 262656 _________________________________________________________________ dense_3 (Dense) (None, 10) 5130 ================================================================= Total params: 669,706 Trainable params: 669,706 Non-trainable params: 0 _________________________________________________________________
These 669706 parameters must have given you a good idea why deep learning models are called ‘black box’ models. With this complicated network, it is absolutely impossible to understand the individual contribution of the 784 input variables to classify the images into digits.
Deep Learning Model & Results
Luckily for us, Tensorflow can easily calculate these weights using the same math we learned in the last part. This deep learning model gives the accuracy of ~98% on the test dataset. This confusion matrix shows that most of the times the deep learning model is right i.e. at the diagonal values.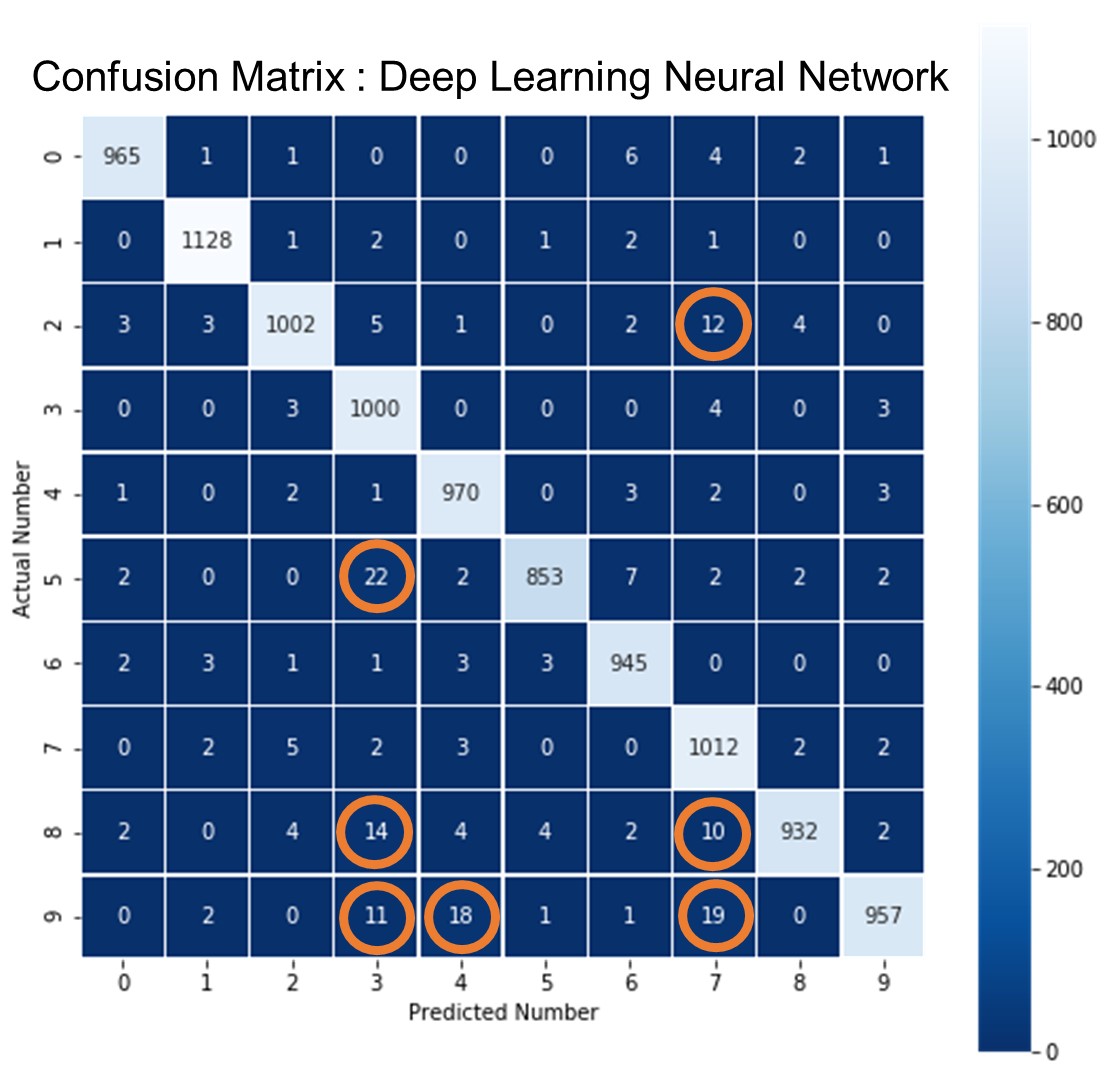
Let’s see where this model has made mistakes by considering more than 10 mistakes of similar kinds. The model has, on occasions, confused 9 with 3, 4 and 7. Also, it identifies 8 as 3 or 7. Moreover, 5 is also confused with 3 on a few instances.
Sign-off Note
Popeye gets his energy from spinach but spinach can be of different qualities as well. A good quality spinach can give higher strength or at least prevent food poisoning or a bad stomach. Similarly, there are ways to improve the quality of input data for deep learning models as well. We will learn the same in the next part when we will explore convolutional neural networks to improve the accuracy further.
Please do you have a course for analytics with Python for someone with no experience in this like zero
Please start a MOOC. You are simply awesome.
Hi Roopam,
Amazing article. Could you please help me understand what made you chose 2 hidden layers and # neurons in each hidden layer.
Thanks,
Tapan
Number of hidden layers is also a hyper-parameter for neural networks. Usually you try out many options before selecting the final model which was not done here. I suggest you try out other combinations yourself, and see if the output improves. Do post your results here for us to discuss.