Data Science Job Interview Types
Are you preparing for a data science job interview? To help you, in this article I will explore some of the most common techniques used by data scientists to select their future colleagues. Additionally, I will also share many sample questions for data science job interviews and suggest a few strategies to prepare. Moreover, please post your comments, questions, and challenges in the discussion section at the bottom. I will be more than happy to help.
Data science job interviews and selection techniques can be categorized into the following 7 classes with 3 levels.
| Data Science Job Interview Type | Level and Significance for Selection |
| 1. Puzzles & Riddles | Level 1 : These are usually the warm-up interview questions to assess logical and analytical aptitude of the candidate. You will rarely get a job offer after clearing only this level. |
| 2. Quick Math | |
| 3. Guesstimation | |
| 4. Programming & Data Preparation Challenges | Level 2 : Things get serious from this stage onward since these are part of daily activities for a data scientist. Some entry level candidates may get a job offer after clearing this level. |
| 5. Statistics & Machine Learning Questions | |
| 6. Case Study Problems / Problem Solving Experience | Final level 3 : This is where the hiring authority is seriously considering you for the position. You will mostly secure an offer after clearing this level. |
| 7. Analyze This / Take Home Analysis |
If you are preparing for a data science job interview it is a good idea for you to know what you might face in these interviews. I will discuss details of these categories of interviews later in the article. I will also introduce a few sample questions from each of these category, and suggest ways to prepare for these interviews. Please share your solution approaches and thoughts for these sample questions in the discussion section of this article.
However, before we explore the selection criteria for data science job interviews & screening process, let us learn about the group of people who have mastered the art of right selection & screening, and they are..
Nigerian Scamsters

Data Science Job Interview – by Roopam
I am sure at some point of time you have received a Nigerian scam mail in your Gmail or Yahoo mail box. These mails are typically from an unknown person desperate to transfer a huge sum of money to your bank account because of turmoil in some African country. The senders of these mails often portray themselves as a high ranking banker or the offspring of some rich person. These emails always have laughable sentences like these
“ …Permit me to inform you of my desire of going into business relationship with you …please feel free to contact ,me via this email address [email protected]” – source for some sample scam mails
Most of us brush these mails off as ridiculous because of their ludicrous language and content. However, the success of these scam mails can be assessed by the following statistics from the report by ultrascan-agi. In 2013 Nigerian scams have duped people with close to 13 billion dollars in financial losses. Moreover between 2006-13 the losses were roughly 82 billion dollars. Now that’s a lot of money and am sure these scam mails have lured a lot of victims. Scamsters are clearly an extremely clever lot, and one wonders why they would write such laughable mails to catch victims.
Nigerian scamsters are indeed a clever bunch. They use these mails as an initial screening process for the intriguing modus operandi of Nigerian scams which eventually requires the victims to transfer money into an unknown bank account that belongs to the scamsters. They are essentially applying this first level of filter to identify people stupid enough to go the distance in this scam. Someone who can’t sight the ridiculous language and absurd content of these mails as suspicious is certainly a great target for these scamsters. The motive of Nigerian scamsters is completely wrong and illegal but their selection process is immaculate to identify and select the right candidate who will go the distance.
Data Science Job Interview
On some level any job interview process, including data science, is far from perfect and is full of flaws. The idea with interviews is to measure the ability of a candidate to run a marathon based on asking them to run a few 100 meter dashes. This is almost impossible. However as we have noticed with Nigerian scammers, they have figured out a quick yet extremely effective strategy to select the right candidates for their purpose. They could do it right because they know clearly who is the right target for them. Even in data science job interviews, the goal is to know clearly what one is looking for in a candidate and design selection procedures around this. Now we will discuss the current practices in data science job interviews.
Level 1 – Data Science Job Interview
Level 1 of data science job interviews is about assessing the logical and analytical aptitude of the participant.
1.1 Puzzles & Riddles
1.2 Quick Math
1.3 Guesstimation
If typical interviews are like a 100 meter dash, these level 1 interviews tend to become a 10 meter ultra fast sprint. They have their place and importance but it is absolutely impossible to assess a candidate purely on these interviews. However, for someone preparing for a data science interview it is a good idea to brush up their skills on these questions. I will suggest a few books later in this article to enhance your skills with puzzles and guesstimations.
1.1 Puzzles & Riddles
Puzzles and riddles are an integral part of interviews at tech companies like Google and Microsoft. In data science interviews expect a few puzzles around probability theory as mentioned in the sample questions.
| Sample Questions:
1) You are at Ranthambore National Park where the probability of sighting a tiger is 95% in every day trip i.e. 8 hours long. What is the probability that you will see a tiger in a half day trip i.e. 4 hours long? 2. Can you explain the solution to Monty Hall Problem? (read the problem and solution approach at this link) |
1.2 Quick Math
Again, expect a few quick maths questions tossed at you during an interview. They are not tough if you have a calculator with you. However during an interview, you will have to solve them without the help of a calculator. What the interviewer looks for in your solution is the ball park figure and not the exact solution to the decimal level.
| Sample Questions:
1. What percentage is 7 of 24? 2. Is 23 times 17 greater than 450? |
These questions are actually useful because data scientists need to check the validity of their results on a regular basis. Having these skills help you sight any glaring discrepancy in your results upfront. It’s highly embarrassing if your customer points them out to you during a presentation.
1.3 Guesstimation Questions
These questions are directly borrowed from the interviews of consulting companies like McKinsey and BCG. Data science profiles usually have a significant amount of work in consulting and customer management. Hence there is a fair overlap between data science and consulting interviews.
| Sample Questions:
1. Estimate market size : How many laptops are sold in India every year? 2. How many tennis balls can you fit in a Boeing 747? |
These two questions for guesstimation on the surface may seem different but they are solved using the same approach. You will find the following books useful for such questions.
Level 2 – Data Science Job Interview
Level 2 of a data science job interview often has:
2.1 Statistics and Machine learning Questions
2.1 Programming and Data Preparation Challenges
2.1 Statistics and Machine Learning Questions
Statistics and machine learning are the key concepts you need to have a good grasp of to be a good data scientist.
| Sample Questions:
1. What are K-mean clusters? Suggest at least a couple of ways to select the optimal value of K. 2. How are artificial neural networks (ANN) different from logistic regression? Can you create a logistic regression model through ANN? How? |
2.2 Programming & Data Preparation Challenges
Data science professionals need to have proficiency in programming languages like R, Python, or SAS. Moreover, they need to understand different strategies to handle and pre-process data. This type of interview usually is an effort to understand the candidate’s proficiency with these skills.
| Sample Questions:
1. What is the largest data size you have handled? What are the challenges you faced while handling that data? 2. What is the command to create histogram in R? |
Personally, I am not a huge fan of asking programming questions (like question 2) in an interview. All data science languages are scripting languages with inbuilt functions for most tasks. I don’t think data scientists need to memorize these functions. Most of the time Google is there to help at work. For instance the answer to 2nd question is hist() – that’s a bit dull. However, you will find a few interviewers asking such questions. You will find many such questions on this site : R Interview Questions. I suggest that while preparing, focus on conceptual and logical angles of algorithms.
Final Level 3 – Data Science Job Interview
The final level of a data science job interview involves:
3.1 Case Study Problems
3.2 Analyze This / Take Home Analysis
3.1 Case Study Problems
These questions are the real deal for many data science job interviews. It makes sense since data scientists need to solve business problems as their primary role.
| Sample Questions:
1. A retail chain is not happy with their return on marketing investment (ROMI); how could you help them improving (ROMI) using business analytics? 2. How could you help a telecommunication company improve on their profitability through data science? 3. How will you build a credit scorecard for a bank? |
These case study interviews often start with broad problem statements like the ones shown above. However, they get extremely detailed as the time progresses during the interview. The candidates are expected to focus more on their approach to solve the problem rather than the final solution.
You will find these case studies on YOU CANalytics useful while preparing for case study problems.
 |
 |
 |
 |
3.2 Analyze This / Take Home Analysis
Analysis of real data is another form of selection procedure that is highly popular among data scientists. In this form of screening process a large data set is provided to the candidate who has to analyse this data. Many times output of this analysis is a complete model e.g. logistic regression, decision tree etc. The candidate is assessed based on the presentation of her thought process, data preparation strategy, exploratory data analysis, and model results. There are several variants of this form of interview. In an elaborated form, the candidate is allowed to take the data back home and is given a few days to work on the data and analysis.
| Sample Questions:
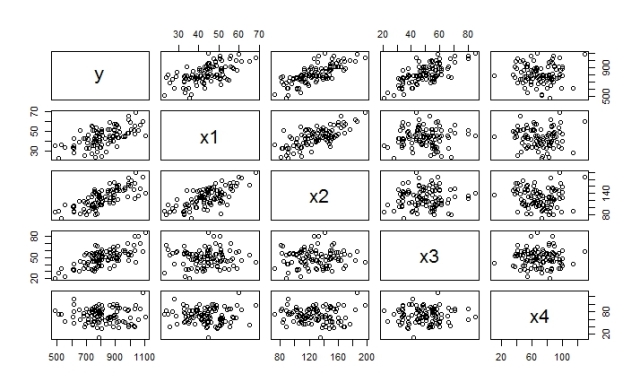
1. Analyse this graph and suggest at least 3 key findings.
2. Consider y as the dependent variable, and x1 – x4 as the independent variables in the multiple linear regression model. What are your expectations about the regression coefficients for this data? Is there something you need to be careful about while generating your regression equation? 3. Attached is dataset for a lending company. Do your analysis and report significant factors responsible for credit defaults. Moreover, prepare a short report / presentation of your approach. |
Sign-off Note
Please share your solution approaches and thoughts for the sample questions discussed in this article in the discussion section at the bottom. Also, feel free to ask your questions, doubts, and suggestions while preparing for a data science job interview. Would love to help.
It would be more helpful if you post answers to with this.
Hey Kaxil,
Yes, will post my answers to these questions soon. However before that, I believe it will be much more fun and good learning if all of us give a shot to these questions collectively. I really look forward to hear your answers.
Cheers,
I justed pass McKinsey interview process, which was very similiar to what you described, and I found tips & examples from their website (http://www.mckinsey.com/careers/join_us/interview_prep) extremely helpful.
Thanks Nika for sharing this, all the best for your career in consulting.
Hi Roopam, Just started following you on Blog. Very interesting anecdote of Nigerian Scam.
Hi Roopman,
Thank for this helpful article. I am pretty new in machine learning and I worked on the lending company dataset.
Sampling 600 entry as the training set, here are my results:
– Decision Tree Classifier: error = 32.3%
– bagging 500 trees: error =24%
– random forrest n=20, error = 28%
– random forrest n=500, error = 24.6%
– SVM (SVC) linear kernel 24%
Any comment or big mistake?
Thanks.
Antoine
I don’t see any glaring descripancy in your results. Decision trees are usually the least accurate algorithms. However, they make up for this lack of accuracy through their simplicity and easy to understand structure. Random forests and bagging trees are ensemble methods with many decision trees hence they almost always perform better than a pure play decision tree. Support vector machines are also doing good here.
Thanks
‘1.3 Guesstimation Questions’ – that’s the proper term for 1.2, since that’s the proper way to solve a questions like ‘what percentage of 24 is 7’.
What 1.3 really is is the bad problem where the ‘ideal process’ is to take a set of numbers whose value is unknown, make very bad guesses, and then to multiply them together. The correct process to answer ‘how many laptops are sold each year in India’ is to find the market research.
P(seeing tiger in 4 hours) = 1 – sqrt(0.05) ~ 77.64%
That’s right.
Hi Ricky,
I’ve been breaking my head over this one. I assume that with 95% sighting certainty, combined with a normal distribution, you can extrapolate what the sighting chance is at 4 hours, which is half the time. I tried to tackle this by finding the number of sigma that equals 95% , cut this in half and then look at the surface area under the normal distribution. However, this is not close to your result and does not explain the calculation you make. Can you tell me how you did this, or which statistical theorem I can google to find the answer since I was unsucessful up till now.
Best regards,
Hans
Hans, let me give you some hints to solve this puzzle before Ricky answers your question.
To begin with, looking for probability distributions or statistical theorems is not the right approach for this problem. Since, I am pretty sure you already know all the statistics and probability required to answer this question.
Now to progress, consider the probability that you will not sight a tiger for 8 hours. Now think, is this probability somehow linked to probability of not sighting a tiger in 4 hours?
Ahaaa, good tip. I got it. Chance of not seeing tiger in 8 hours=0.05. So chance per hour of not seeing tiger is p(notiger1hour)^8=0.05 which means P(notiger1hour)=0.6877. So chance of no tiger in 4 hours is 0.6877^4=0.2236. So chance of tiger in 4 hours is 1-0.2236=0.776. Hmm, I guess I was thinking way too complicated and not following KISS here (Keep It Simple Stupid) ;-), thanks! I’m convinced you’re also a KISS follower 😉
Is the simple answer given by Ricky (of squareroot) because 4/8 is half the power?
Hi Ricky, I went to p(notiger1hour) but you could also go to:
p(notiger4hours)^2=0.05
p(notiger2hours)^4=0.05
so
p(notiger4hours)=sqrt(0.05) as you mentioned so p(tiger4hours)=1-sqrt(0.05)
Answers to the graph question 1: 3 Key findings:
x1 is correlated ty Y and is a good predictor
x2 is correlated to Y and is a good predictor
x3 is correlated to Y and is a good predictor
x1 and x2 are correlated among each other, so you could write one as a function of the other simplifying the model.
x4 is not correlated to Y or any other variable so you can leave it out.
Most simple form for a model would be (using above statements) Y=A*x1+C*x3+E
answer to 2:
You can find the ‘rate of climb’ for each of the graphs. I don’t see what I have to be careful about except for throwing out the variables that have no correlation and you have to be careful reading the scales. Maybe a linear regression algorithm could generate a vertical line in a cloud of points (for the uncorrelated variable(s) ) which could cause a very wrong outcome, maybe that’s what you have to be careful about.
Interesting. I would use a completely different approach here.
As X1 and x2 are correlated, I would drop either x1 or x2 as they appear to explain the same pattern and therefore inclusion of both with inflate variance. I would validate this with a stepwise model (ANOVA) to see if the inclusion of x2 adds the probability.
X3 is correlated with y but not x1 so suggests it could be included, though again the stepwise function will help here.
Also it could be that the first variable is masking the trend in x4 and so I would look to create a chart of correlation of x4 to y once the x1 is controlled for.
PS excellent article. This really helps for my interview prep.
Hi James,
Thanks for your view on the graphs, very insightful approach. Can you share your internal thought process behind the idea that X1 is masking a trend in X4. Do you have some quantitative reasoning behind that looking at the scales of the graphs?
Simpons paradox is an excellent example of this. The relationship reverses when another variable is added. It’s a possibility and so whilst exploratory analysis like this is a great first step, you can’t use it to build the entire model in 1 go. You need to repeat the process for the next step.
Hi James, So the approach is to first remove x1 and/or x2 from the data, to reveal if x3 is significant. Then you remove x3 as well to see if x4 is significant. Just like the arima model in the manufacturing case study where you remove the trend first to reveal the seasonality better.
Hi Roopam,
Indeed your new post is very detailed and informative touching each aspect. I am a steadfast reader of your analytics blog and definitely helped me in many ways.
Thanks,
Debasish
What is the difference between decision tree and regression?