“Data! Data! Data!” he cried impatiently. “I can’t make bricks without clay.”
– Sherlock Holmes

Data Simulation & Creation – by Roopam
This is a continuation of our regression case study example. In the previous parts, we have learned, as Sherlock Holmes says, to make bricks i.e. develop regression models. In this part, we will learn how to make clay from scratch i.e. create raw data through data simulation. Data simulation is a great way to learn the deeper nuances of modeling and analysis. Since we cook up our own data in data simulation, we can test if the model is capturing the patterns we had hid in the data. In this article, we will simulate the data we had used for the last 5 parts of this case study example. We will also go back and see if our models had decoded our encryption. You can find all the parts of this case study at this link : Regression Case Study Example.
After reading this article, I suggest you simulate more datasets and analyze them to learn nuances of analysis and regression. I have learned a great deal about data science through data simulation. Data simulation empowers analysts, in an extremely small way, to play God. Let’s see how.
Data Simulation and Creation Myths
How did the universe and humans come to being? In the modern world, it is scientifically accepted that the Big Bang created the universe and evolution produced humans from primitive life forms. But before these scientific theories were developed and tested, most cultures had their mythical stories about the creation of the universe, the earth, and humans by mythical characters. These stories are referred to as creation myths.
For instance, Genesis, the first book of the Bible, describes that God created the entire universe in seven days. The story goes that God created day and night on the first day followed by other stuff in the universe on the subsequent days. He made animals and humans on the sixth day and rested on the seventh. Based on references in the Bible, the age of the universe is estimated close to 6000 years. The actual age of the universe calculated by scientists is roughly 14 billion years. That’s a massive calculation error when estimating the age of the universe using the Bible.

Drawing Hands – M.C. Escher
Ok so let’s forget about science for now and imagine that this creation myth is true. God created the universe 6000 years ago. Now, let’s also imagine that God has decided today to analyze his creation piece by piece. Will he find everything the same as when he had created the universe? The answer is no since all these elements of the universe are interlinked in a complicated fashion with each other. The creation, in this case, has taken a shape of its own. Complex and intertwined systems have this tendency,
Data simulation empowers analysts to create reasonably complicated datasets through random numbers. Also, like God’s creation, if the data is complicated, it has the power to surprise analysts at the time of analysis like natural systems. Mathematical simulations are used by scientists to study complicated natural phenomena like turbulence, financial markets, weather patterns, quantum mechanics, chaos etc. Monte Carlo simulations are used extensively in risk modeling.
I must also say that simulation is good fun. After all, how often do you get the chance to play God? Let’s go back to our case study example and simulate some data.
Data Simulation for Regression Case Study Example
We are simulating the data we had used in this Regression Case Study Example. If you could recall, we had 8 predictors or independent variables in this regression dataset, and a numeric response or dependent variable i.e. house price.
| Variable Type | Variable Name | Features |
| Numeric independent variable | Dist_Taxi | Distance to taxi stand, market and hospital are correlated |
| Dist_Market | ||
| Dist_Hospital | ||
| Carpet Area | Carpet and built-up area are highly correlated | |
| Built-up Area | ||
| Rainfall | Random variable | |
| Categoric independent variable | Parking | 4 categories |
| City_Category | 3 categories | |
| Numeric dependent variable | House_Price | To predict with dependent variables |
Based on the requirements, these are our objectives for data simulation:
- Create 3 correlated variables: distance to taxi, market, and hospital using a correlation matrix
- Create 2 highly correlated variables: carpet area and built-up area
- Create categorical variables: parking and city category. Also, create a random variable rainfall.
- Create a dependent variable with a defined relationship with some of the independent variables
Objective 1. Create Correlated Variables by Cholesky Decomposition
The first thing we need to define is the correlation matrix for the 3 numeric variables i.e. distance to taxi, market, and hospital.
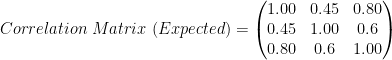
Cholesky decomposition is a powerful mechanism to generate correlated variables from the random numbers as displayed in this schematic.

Essentially, first, you decompose the expected correlation matrix through Cholesky decomposition. Then multiplication of the Cholesky component with random numbers generates the desired data set.
This R code generates Cholesky components of the correlation matrix as required.
Corrlation.Matix = matrix(cbind(1,.45,.8, .45,1,.6, .8,.6,1),nrow=3) Cholesky = t(chol(Corrlation.Matix))
Now we will multiply the Cholesky component with 3 normally distributed random variables to produce correlated variables i.e. distance to taxi, market, and hospital.
set.seed(2)
random.normal = matrix(rnorm(3*930,8000,2500), nrow=3, ncol=930)
Data = as.data.frame(t(Cholesky %*% random.normal))
names(Data) = c("Dist_Taxi","Dist_Market","Dist_Hospital")
Okay, so let’s see how the transformation worked by calculation of correlation matrices. First, let’s estimate correlation matrix for the random variables.
cor(t(random.normal))
As expected, there is a poor correlation between the 3 random variables.

Now, let’s see the correlation of data generated through the transformation of these random variables by Cholesky decomposition.
cor(Data)
Not bad, this data has the correlation matrix quite similar to the expected correlation matrix.

We have accomplished our first objective for data simulation. Now, let proceed to the second objective.
Objective 2. Create 2 Highly Correlated Variables
We can use Cholesky decomposition to generate these variables. However, let’s try something different. We will generate the first variable i.e. carpet area through a random normal distribution.
set.seed(245) Data$carpet = rnorm(930,1500,250)
Now, we will add a tiny bit of noise to carpet area to produce the second variable i.e. built-up area.
Data$builtup = Data$carpet+rnorm(930,.2*Data$carpet,.01*Data$carpet) cor(Data$carpet,Data$builtup) Data = round(Data,0)
Since we have added just a small fraction of noise, the correlation between the two variables turned out to be quite high i.e. 0.998. This is an almost perfect correlation. You may want to play around with the noise factor, random normal distribution i.e. rnorm parameters, to see how correlation varies with different inputs.
We will also use this same method for adding noise to our final model.
Objective 3. Create Categorical Variables
Now, we will generate categorical variables: parking and city category. For parking, we will use a predefined probability distribution to generate four classes in this categorical variable.
set.seed(5)
Data$parking = as.factor(sample(c("Open", "Covered", "No Parking", "Not Provided"),size = 930, prob = c(0.4, 0.2, 0.15, 0.25),replace = TRUE))
Similarly, we will also generate 3 classes of city category.
set.seed(20)
Data$City_Category = as.factor(sample(c("CAT A", "CAT B", "CAT C"),size = 930, prob = c(0.35, 0.4, 0.25),replace = TRUE))
Finally, we will generate the last independent variable: rainfall. This variable will have no correlation with the other independent variables or the dependent variable i.e. house price.
set.seed(30) Data$rainfall = round(rnorm(930,80,25),0)*10
Objective 4. Create Dependent Variable with Relationship to Independent Variables
I am sharing the method I used to generate the data for the regression case study example but I seriously recommend that you play around with different combinations of the relationship between the dependent and independent variable and make different regression models. Trust me, from the practical point of view, there is no better method to learn about aspects of modeling than simulating data and developing models with the simulated data.
require(FactoMineR) pca1 = PCA(Data[,1:5]) Data = cbind(Data,pca1$ind$coord[,1:2]) Data = cbind(Data,model.matrix( ~ parking-1, data=Data),model.matrix( ~ City_Category-1, data=Data))
For this case study example, I took the principal components of the dependent variables and used the first two components (Dim.1 and Dim.2) in the model. Moreover, I had converted categorical variables into dummy variables (code line 23) to be used in the model. This is the equation that I had used to create the independent variable (house price).
set.seed(253) Data$price = (round((Data$Dim.1+abs(Data$Dim.1)+1)*1.85+(Data$Dim.2+abs(Data$Dim.2)+1)*1.39 +rnorm(930,30,12),digits = 2)+ (Data$`City_CategoryCAT A`*35+Data$`City_CategoryCAT B`*17+Data$`City_CategoryCAT C`*8)+ (Data$parkingCovered*4+Data$parkingOpen*1.5+Data$`parkingNo Parking`*0.45))
Data$price = Data$price*10^5
I will let you check whether our regression models in the last part had deciphered this equation.
Sign-off Note
Usually, natural phenomena are captured by humans in the form of data. Simulation empowers humans to generate their own data and hence in a small way allows them to be powerful like nature. If you prefer a more dramatic definition for nature call it God. Enjoy playing God while you simulate and learn more about regression modeling.
Loved this series! I have been looking for resources to help figure out how to make the best use of PCA and this is hands down the most straight forward way to get the basics of it. Is there any chance in the future of getting a series on Factor Analysis?