
The chimpanzee genome is more than 95 % identical to the human genome – by Roopam
Evolution of Biology & Medicine with Big Data
I learnt a couple of facts when I was around 14 years old. First, that the chimpanzee genome is more than 95% identical to the human genome. Second, that the genomes of two different humans is 99% identical. The genome is the building block of life. I struggled with the fact that something that is less than 1% different has produced Hitler, Gandhi, Einstein and Madonna. Before we try to figure out how this is possible let us revisit a few basic concepts of biology.
Genome and Computer Code – Analogy
The genome is the code of life. It works similar to a computer code where you punch in the functionalities and rules for the end software like Excel or Word. The genome is made up of a chemical called DNA – DeoxyriboNucleic Acid. The fundamental unit of a computer code is binary i.e. it can take two values 0 or 1. Similarly, DNA’s fundamental unit has four values A, T, G and C – recorded in terms of base pairs. The human genome has approximately 3 billion base pairs.

The Computer Code and Organic Code (DNA) are quite similar
Now when we say that there is around 1% difference in the genomes of two different humans it means 30 million base pairs of difference. Additionally, since each of these 30 million base pairs can take four values (A, T, G, and C). This means we could pack information in (30 million)4 or 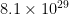 different ways in two humans. This number is significantly more than the number of stars in the universe. To put this in perspective, Windows-7 occupies around 10 Gigabytes of space on the computer. 10 GB is about 8.6 billion bits. Since a bit can take two values (0 & 1), we have (8.6 billion)2 or
different ways in two humans. This number is significantly more than the number of stars in the universe. To put this in perspective, Windows-7 occupies around 10 Gigabytes of space on the computer. 10 GB is about 8.6 billion bits. Since a bit can take two values (0 & 1), we have (8.6 billion)2 or  ways of storing information. Therefore, I guess if you could create the difference between Windows and Mac OS with far lesser information, Hitler and Gandhi are possible with just 1% difference in their genomes.
ways of storing information. Therefore, I guess if you could create the difference between Windows and Mac OS with far lesser information, Hitler and Gandhi are possible with just 1% difference in their genomes.
Human Genome is Big Data
Now, if you consider an analysis of the complete human genome we are talking about big data analysis. This is exactly the new wave of research in modern biology, as discussed in a previous article. It took scientists a decade to sequence 3 billion base pairs of the human genome when they first completed the job in 2003. However, now they can do the same task in a day’s time. This data has all the three Vs of big data:
1. Volume – the data is huge and generated at multiple facilities
2. Velocity – the data is generated at a fast pace
3. Variety – the data is in different formats (numeric, picture etc.)
In this article, we will learn about the trends in modern biology and take up an applied research question to understand this phenomenon better in the context of big data.
Big Data in Pharmaceutical Industry – Genomics
The roots of modern biology, also known as molecular biology, are quite recent. James Watson and Francis Crick elucidated the structure of DNA in 1953 and started the revolution in molecular biology. The pharmaceutical industry spends billions of dollars per year for research in the field. The dividends of this effort are quantum leaps in medical facilities and drug discoveries. The diseases that were termed as death sentences a few years ago are now curable.
Before we get into details of big data for modern biology and medicine, let us ask – how can the genome play such a big role in these areas? In fact, proteins are the main players in most diseases. Proteins are to living creatures as machines and workers are to factories: they carry out all the important functions in living creatures. Therefore, if a protein (worker/machine) started misbehaving then the factory (living creature) would be in trouble. In diseases, there are rogue proteins that mess up the entire smooth functioning tissues and organs.

DNA–> RNA–>Protein and Big data techniques to extract near complete information about them – by Swati Patankar
The broad mechanism of using DNA as an information carrier to make the proteins is a well-known phenomenon, as shown in the adjacent diagram. However, as I have mentioned before on several occasions, the devil is in the details and so is all the fun. This is the task molecular biology tries to accomplish, to uncover every aspect of the DNA and protein in a particular normal or diseased tissue. If accomplished, we could eradicate diseases with a genetic basis like cancer, diabetes, obesity, etc.
Traditionally, molecular biology tried to study some specific region in the genome or a specific protein at a time. These specific regions are called genes – the region that codes all the proteins. There are roughly 30 thousand genes in the human genome. However, with the advent of a newer technique called genomics a researcher can study all the genes at the same time. This technique generates a plethora of data to be analysed. Yes, molecular biology has made the leap from small to big data through genomics.
Biostatistics for Cancer – Correlation vs. Causation
Cancer, a disease, was a black box for the most part of human civilization, has started revealing itself because of developments in modern biology. Cancers are further divided into invasive and non-invasive forms. The invasive form of a cancer spreads to nearby tissues and hence is much more dangerous. If a physician can predict the form of cancer beforehand, she can devise a suitable therapy for the patient. A much more aggressive therapy is required for invasive cancer. If you want to go to the roots of cancer, you cannot go any closer than DNA – hence we have genomics to our rescue.

Gandhi – by Roopam
A biostatistician has her work cut out for this predictive modeling problem – to distinguish between invasive and non-invasive cancer beforehand. From our previous discussions on credit scoring, you must have guessed this problem is somewhat similar to the classification of good / bad loans. However, in this case, the input variables are mutations or expression of 30 thousand odd genes extracted through genomics. The final model is going to help the physician in diagnosing the type of cancer and suitably designing the therapy.
The above is an example of finding the correlation between the gene expressions and the forms of cancer – this is extremely useful in diagnostics. However, for drug discovery correlation can only serve as the beginning. Establishing causation and drug discovery is a long and tedious process but still the most desired one. In absence of causation, one could just predict that something bad is going to happen but cannot do much to stop it. This is a fairly helpless situation. Although difficult, causation has been shown for many cancers and drugs have been developed that do prolong the life of patients. Herceptin is one such example.
Sign-off Note
The correlation helps us distinguishing between Gandhi and Hitler beforehand. However, understanding causation can produce more Gandhis in the world. Having said this, both correlation and causation have their place in science.
I should thank my wife, Swati, for helping me out with this article.