Welcome back to our digital marketing case study example. In the previous part, you had initiated an email donation campaign for your client Helping Hand, an NGO, with three different ads for the same cause to support the needy in Africa. The idea is to identify the ad that generates the maximum donation from the email recipients.
In this part, you will analyze the data from this campaign. You will use A/B testing, a widely used method in digital marketing, to test the effectiveness of different ads. You will also identify shortcomings of A/B testing. In the next parts of the case study example, you will devise a robust method to improve A/B testing using concepts from Bayesian statistics and reinforcement learning (a method used in the development of artificial intelligence and intelligent systems).
Before we learn the technical subtleties of A/B testing, let’s explore how A/B testing is similar to Olympic events.
A/B Testing – Who Wins the Race?

A/B Testing and Photo Finish – by Roopam
At the Rio 2016 Olympic Games, the women’s 400-meter sprint final witnessed a dramatic finish. Allyson Felix of the USA was the favorite going into the race, with four Olympic gold medals already in her tally. Shaunae Miller from Jamaica was her biggest challenge. At the beginning of the race, Miller took a sizable lead. Felix, being the champion she was, sprinted through the last leg and started inching ahead of Miller. Felix was all set to win another gold. This was when something incredible happened. Shaunae Miller, in her final effort to win the gold, dived across the finishing line. It was a photo finish between Felix and Miller. Initially, to the naked eyes, it seemed that Felix had won. The results from the ultra-slow motion, however, showed that Miller beat Felix by less than a tenth of a second to win the gold.
Many playfully asked if Miller should get the gold for sprinting or diving. A statistician, however, will ask a different question: If you repeat the final moments of this race many times (say 100), how many times Shauna Miller will win the race? Miller, to me, didn’t look completely in control of that dive. I will put my money on Allyson Felix to win more than 75 times out of 100 races. This number is a wild guess but the greater odds were in favor of Felix. The final results saw Miller winning the gold. This is an important lesson in statistical thinking that higher odds and final outcome could be different.
A/B testing is very similar to an Olympic race as we will see in our digital marketing case study example in the next segment.
Click Through Rate – Case Study Example
In this case study example, you are identifying the best ad/message to generate the maximum donation from an email campaign. Essentially, it is a race between these three advertisements to win the gold.
In an Olympic race, the performance measure is well-defined i.e. fastest to finish. Similarly, we need to define the performance measure for these banners before making them compete in a race. To do so, let’s look at the life cycle and associated metric for an email campaign.

The life cycle of email campaigns has several metrics to measure the performance of the campaign as displayed in the schematic.
Delivery and Bounce Rate
You are an expert in digital marketing and campaigns and are aware of expected standards for these metrics for a campaign like yours. For instance, you expect a high bounce rate of 8-12% for the emails because these email IDs were collected on a paper form. This means if 1000 emails were sent out then approximately 100 of them will bounce (remember MAILER-DAEMON in your email box). This makes the email delivery rate as:
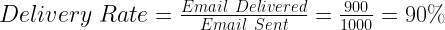
Open Rate
Now, some of the recipients of these delivered emails will open the mail to check the content of the mail. Other mail will either go into the spam folder or get deleted without being opened. You expect this rate to be 8-15% for your campaign.
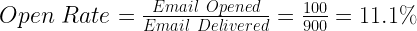
Click Rate
Moreover, each of these ads has a specific call-to-action in the form of hyperlinks for the interested donors which says ‘know how you could help’. Some of these opened emails will have a click on the hyperlinks. This initial interest of email recipients will be registered as the click rate. You expect the click rate to be between 10-20% for your campaign.

Finally, some of these clicks will generate the actual donation in the form of hard cash. This is the last mile for this campaign.You will notice that a small fraction of 1000 emails sent will generate the actual donation. This is registered as conversion rate and actual donation amount.
Performance Measure for A/B Testing – Case Study
In this case study example, you are interested in learning about the effectiveness of the three ads for donation. In the campaign lifecycle, the effectiveness of these ads is between the open and click stages. Hence, the right performance measured for the ads is click rate. You had kicked off the campaign with 27000 emails. It is barely an hour since the emails were sent and you have some initial results from the campaigns.
| Ads | Total Emails Sent | Clicks (1st hour) | Opens (1st hour) |
| A | 5500 | 4 | 58 |
| B | 9000 | 14 | 101 |
| C | 12500 | 23 | 129 |
The first thing that your client notices when she saw these numbers is that you have not distributed the sent email evenly across 3 ads i.e. 9000 per ad. Incidentally, ad-A has received just 20.4% of email vs 46.3% for ad-C. She is a bit confused about this distinction but you assure her that you are using the principles of reinforcement learning for sampling the emails to maximize returns. She seems assured for now but would like to learn more about this seemingly odd sampling methodology later. Before she leaves for a meeting, you promise her that you will be more than happy to explain the details when you meet her after a few days.
Now that you are left alone and have some time in hand you analyze the initial results from the campaign. You are aware that the first hour’s click rate is not a good representation of the campaign’s performance. The ideal time to measure an email campaign performance is between 7-10 days. But you do the analysis anyway to brush up your skills for A/B testing before you get the comprehensive data after few days.
A/B Testing or Hypothesis Testing of the Campaign Results
A click rate is a form of Bernoulli experiments where only two outcomes are possible i.e. clicked (1) and not clicked (0). A/B testing is essentially a hypothesis testing of proportions i.e. the click rates. The null hypothesis or status quo is that all the ads are the same in terms of the performance or click rate (π) which is represented as:
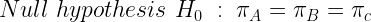
A more interesting scenario will be if one ad outperforms others and wins the gold. After all, a three-way tie is a boring race. We will identify the winner using hypothesis testing or A/B testing. These are certain underlying sample requirements that the experiment needs to satisfy to do a scientific hypothesis testing. We need to have at least 10 instances of both clicks and non-clicks. This requirement can be relaxed to 5 clicks/non-click with a few caveats but the sample size should never fall below 5. You notice that for ad-A you have just 4 clicks which are not a sufficient sample size. Hence, you can only compare performance for ad-B against ad-C. Let’s first find the click rate for ad-B:
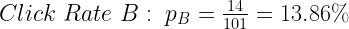
Similarly, the click rate for ad-C is:

17.82% is much better than 13.82% or is it? Remember when we hypothetically made Allyson Felix and Shaunae Miller run 100 races. Let’s do the same to ad-B and ad-C to test their performance.
R code and Results
The best part is a simple one line of R code could do this job for us.
prop.test(x = c(14, 23), n = c(101, 129), correct = FALSE,alternative = "greater")
R shows the following result on the console. You could test this code on this Online R compiler if you don’t have R installed on your system.
2-sample test for equality of proportions without continuity correction data: c(14, 23) out of c(101, 129) X-squared = 0.66075, df = 1, p-value = 0.7919 alternative hypothesis: greater 95 percent confidence interval: -0.1188712 1.0000000 sample estimates: prop 1 prop 2 0.1386139 0.1782946
The most important part in this result is the p-value of 0.7919 ~ 0.79. This, on some level, means ad-C will beat ad-B in 79 races out of 100. On the other hand, ad-B will win just 21 races. That’s not good enough. Incidentally, statisticians are the fans of p-value = 0.95 or a competitor beating the other in more than 95 races out of 100. Based on these results, ad-C is not significantly better than ad-B.
Final Results of the Campaign and Questions from Your Client
After a week of rolling out the email campaign, you client shares the results of the campaign. These results could be considered as final for the campaign because waiting for more days will not change these numbers much.
| Ads | Total Emails Sent | Clicks (5 days) | Opens (5 days) |
| A | 5500 | 41 | 554 |
| B | 9000 | 98 | 922 |
| C | 12500 | 230 | 1235 |
Now, you are on your own to analyze this data.You may find this Online R compiler useful. You need to answer these questions posed by your client.
|
Report your answers to your client in the comments section at the bottom of this post. Share your thoughts and questions as well.
Sign-off Note
If you remember, you had prior knowledge of the results for your campaign results i.e. 10-20% 0f click rate base on your experience. You, however, did not use that prior knowledge in your analysis. A/B testing in its classical form (i.e. Fisherian statistics) has this problem. The whole purpose of knowledge is to grow incrementally. Otherwise, each analysis is performed in isolation without linking it to the prior knowledge. In the next article, we will explore how Bayesian statistics could be used to improve A/B testing by usage of the prior knowledge.
Hi Roopam,
The results for B and C as follows:
data: c(98, 230) out of c(922, 1235)
X-squared = 26.166, df = 1, p-value = 3.133e-07
alternative hypothesis: two.sided
95 percent confidence interval:
-0.10939210 -0.05049619
sample estimates:
prop 1 prop 2
0.1062907 0.1862348
from result p-value = 3.133e-07, which is very very low value to analysis.
it means out of 10^7 attempts B beat C 3 times only which very poor performance.
can you please explain about X-squared = 26.166, df = 1, p-value = 3.133e-07 ?
what is the math behind above said parameters and how interpret them ?
Thanks in advance…….
The mathematical logic behind this is that 98 clicks out of 230 trials are Bernoulli experiments. This is similar to coin tosses. Bernoulli trials make a binomial distribution which can be approximated as a bell curve or normal distribution curve.
Essentially, when you compare 98 successes (clicks) out of 230 opens/trials with 922 success of 1235 trials you are comparing two bell curves. The mean for the first bell curve is 98/230 and its standard deviation is sqrt(98/230*(1-98/230)*(1/230)). You could find the mean and sd for the second curve in the same way.
Now to compare these bell curves. When you say p-value = 3.133e-07, this means that only 3 times out of ten million occasions curve A is equal or same as the curve B. This is the same conclusion you made. This is the only thing one needs to understand rest is all technical jargon.
The p-value result from prop.test is not fully clear to me.
Let’s say that for the “A beat B” testing we increase the #clicks from 41 to 61…the p-value is intuitively increasing (from 3.976095 to 81.88154) but when further increasing the #clicks to 81 we get a lower p-value (2.291782) as per the below…looks quite odd and counterintuitive.
> prop.test(x = c(41,98), n = c(554,922), correct = FALSE)$p.value*100
[1] 3.976095
> prop.test(x = c(61,98), n = c(554,922), correct = FALSE)$p.value*100
[1] 81.88154
> prop.test(x = c(81,98), n = c(554,922), correct = FALSE)$p.value*100
[1] 2.291782
An important argument about hypothesis testing was missing in the r-codes (i.e. alternative = “greater”). This could be causing the confusion. The new results are:
> prop.test(x = c(41,98), n = c(554,922), correct = FALSE,alternative = “greater”)$p.value*100
[1] 98.01195
> prop.test(x = c(61,98), n = c(554,922), correct = FALSE,alternative = “greater”)$p.value*100
[1] 40.94077
> prop.test(x = c(81,98), n = c(554,922), correct = FALSE,alternative = “greater”)$p.value*100
[1] 1.145891
In this example, there are two ads A and B racing to get to the finish line first. In the first calculation, the average speed of B is 98/922=10.6 (I know this is click rate but speed is easy to follow). Similarly, the average speed of A is 41/554=7.4. In this case, B will beat A more often i.e ~98%. In other words, A will beat B in 2 races out of 100. Also remember, the standard deviations for these two racers is making them run faster or slower in different races. That’s why B is not winning every single race despite having a higher average speed than A.
In the second case, A has the average speed of 61/554=11.01 vs. B’s 10.6. This is a relatively close race hence B is beating A in 40.94 ~41 races out of 100.
In the third case, A is running much faster with the average speed of 14.6 against 10.6 for B. Hence, in this case, A will win in ~99% races.
That’s very confusing…can you then confirm me in the first and second case the p-value can be interpreted as the probability of adA being superior to adB while in the third case is the other way round (adB being superior to adA)???
Hi, I just noticed an important argument about hypothesis testing was missing in the r-codes. I have made the corrections in the article as well. This could be the reason for some of the confusion. Try these codes with the alternate hypothesis of greater or (alternative = “greater”). I have made changes to my previous comment based on this.
I agree Roopam…you have explained pretty well and detailed with results.
Thank you for that.
Could you also tell us the difference here between :
(alternative = “greater”) and alternative hypothesis: two.sided
as well
The null/alternative hypotheses in both these cases are different i.e. by default you are testing A=B, whereas with alternative = “greater” the test is for B>A.
Hi Roopam
Why did you not distribute the 3 emails campaigns evenly and how do you choose the sampling?
Thanks!
Laurence
Hi, Laurence.
I have addressed this question in part 4 of this article – Thompson Sampling for Artificial Intelligence.
Just to give you a heads up, we are using Thompson Sampling to design the sample sizes. Thompson Sampling is a method that tries to optimize both explore and exploit at the same time. This is related to reinforcement learning we had discussed in the previous part of this article. Let me post part 4 soon with details.
i really like the post .please keep on posting such kinds .especially when you allowed us to do the testing ourselves..
Loved it
Roopam sir,this blog is the first of it’s kind.Awesome!
could you please let me know the solution for finding the best ad among those 3 variations?I’ve faced the same exact question in my interview and I’m very fortunate to have come across this blog.
similarly if I need to find out the best ad among 4 variations(a,b,c,d),do i need to do the test for the combinations ab,bc,cd,da,bd?
Hoping for a quick reply pls 🙂 ….have another similar interview shortly 🙂
Since you are interested in the winner or the best ad, you don’t need to do pair wise tests. You just need to test whether the best ad (with the highest click or conversion rate) is significantly better than the second best ad. The only catch is if the sample sizes are statistically significant across all groups – since this is a scientifically designed experiment you could make that assumption and state that to your interviewers. If the assumption is not accurate then compare the best ad with all others. Usually a quick look at the data helps in making such judgements.
Thank you sooooo much sir,this greatly helps!
the question that i was asked had 1 control group,4 test groups.
in all these cases,do i need to conduct the test separately for each combination (ab.bc.cd…etc.) ?
the question that i was asked had 1 control group,4 test groups.
in all these cases,do i need to conduct the test separately for each combination ?
Hi Roopam,
This is a great article! Thank you for posting it. However, I have two questions –
1. What is your reasoning behind selecting different sample sizes for the total emails sent in each case – A, B, C
2. In the above response, what do you mean by statistically significant sample size? (you mean greater than 50?)
4. Isn’t this a case for 1-way ANOVA?
Thanks. To answer your questions :
1) Read the last part of this case study where the reason for unequal sample size is explained http://ucanalytics.com/blogs/thompson-sampling-for-artificial-intelligence-digital-marketing-case/?relatedposts_hit=1&relatedposts_origin=9951&relatedposts_position=0
2) For experiments with binary outcomes, a statistical significant sample implies having at least 10 samples of both the cases. You could relax this condition to 5 samples of both cases but no lesser.
3) Not Anova but the Chi-Square test. The t-test is a special case with binary classes of the Chi-Square test which is also relevant for multiple classes. Anova is for continuous variables.
That makes sense. Thank you very much for your explanations!
1. I was considering the click rate as a continuous variable. So essentially, since the response variable is binary, we can either do a Chi-Squared test of association where both the response and the explanatory variables are categorical or the special case of binary class t-test?
One more doubt that I have is-
2. In this particular example, you have conducted a two-sample test where it is easy to say which category is the best. But let’s say we have a case of anova, where we have a continuous response variable and and 4-level categorical predictor variable. Once you reject the null, you can only say that at least one of the 4 levels is significantly different from the rest. But how can I know which one is the best of them all? Is there any test for that?
Best,
Sanya