The Beautiful Formula

The Beautiful Formula – by Roopam
Mathematicians often conduct competitions for the most beautiful formulae of all. The first position, almost every time, goes to the formula discovered by Leonhard Euler. Displayed below is the formula.

This formula is phenomenal because it is a combination of the five most important constants in mathematics i.e.
0 : Additive Identity
1 : Multiplicative Identity
π : King of geometry and trigonometry
i : King of complex algebra
e: King of logarithms
It is just beautiful how such a simple equation links these fundamental constants in mathematics. I was mesmerized when I learned this Euler’s formula in high school and still am. Euler is also responsible for coining the symbol e (our king of the logarithm), which is sometimes also known as Euler’s constant. The name is an apt choice for another reason – Euler is considered the most prolific mathematician of all time. He used to produce novel mathematics at an exponential rate. This is particularly startling since Euler was partially blind for more than half his life and completely blind for around last two decades of his life. Incidentally, he was producing a high-quality scientific paper a week for a significant period when he was completely blind.
Today, before we discuss logistic regression, we must pay tribute to the great man, Leonhard Euler as Euler’s constant (e) forms the core of logistic regression.
Case Study Example – Banking
In our last two articles (part 1) & (Part 2), you were playing the role of the Chief Risk Officer (CRO) for CyndiCat bank. The bank had disbursed 60816 auto loans in the quarter between April–June 2012. Additionally, you had noticed around 2.5% of bad rate. You did some exploratory data analysis (EDA) using tools of data visualization and found a relationship between age (Part 1) & FOIR (Part 2) with bad rates. Now, you want to create a simple logistic regression model with just age as the variable. If you recall, you have observed the following normalized histogram for age overlaid with bad rates.

We shall use this plot for creating the coarse classes to run a simple logistic regression. However, the idea over here is to learn the nuances of logistic regression. Hence, let us first go through some basic concepts in logistic regression.
Logistic regression
In a previous article (Logistic Regression), we have discussed some of the aspects of logistic regression. Let me reuse a picture from the same article. I would recommend that you read that article, as it would be helpful while understanding some of the concepts mentioned here.

Logistic Regression
In our case z is a function of age, we will define the probability of bad loan as the following.

You must have noticed the impact of Euler’s constant on logistic regression. The probability of loan or P(Bad Loan) becomes 0 at Z= –∞ and 1 at Z = +∞. This keeps the bounds of probability within 0 and 1 on either side at infinity.
Additionally, we know that probability of good loan is one minus probability of bad loan hence:

If you have ever indulged in betting of any sorts, the bets are placed in terms of odds. Mathematically, odds are defined as the probability of winning divided by the probability of losing. If we calculate the odds for our problem, we will get the following equation.
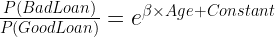
Here we have the Euler’s constant stand out in all its majesty.
Coarse Classing
Now, let create coarse classes from the data-set we have seen in the first article of this series for age groups. Coarse classes are formed by combining the groups that have similar bad rates while maintaining the overall trend for bad rates. We have done the same thing for age groups as shown below.

Table 1 – Coarse Class
We will use the above four coarse classes to run our logistic regression algorithm. As discussed in the earlier article the algorithm tries to optimize Z. In our case, Z is a linear combination of age groups i.e Z = G1+G2+G3+Constant. You must have noticed that we have not used G4 in this equation. This is because the constant will absorb the information for G4. This is similar to using dummy variables in linear regression. If you want to learn more about this, you could post your questions on this blog and we can discuss it further.
Logistic Regression
Now, we are all set to generate our final logistic regression through a statistical program for the following equation.

`
You could either use a commercial software (SAS, SPSS or Minitab) or an open source software (R) for this purpose. They will all generate a table similar to the one shown below:
| Logistic Regression Results (Age Groups and Bad Rates) | |||||
| Predictor |
Coefficient |
Std. Er |
Z |
P |
Odds Ratio |
| Constant |
-4.232 |
0.074456 |
-56.84 |
0 |
|
| G1 |
1.123 |
0.103026 |
10.9 |
0 |
3.07 |
| G2 |
0.909 |
0.0919 |
9.89 |
0 |
2.48 |
| G3 |
0.508 |
0.082846 |
6.14 |
0 |
1.66 |
Let us quickly decipher this table and understand how the coefficients are estimated here. Let us look at the last column in this table i.e. Odds Ratio. How did the software arrive at the value of 3.07 for G1? The odds (bad loans/good loans) for G1 are 206/4615 = 4.46% (refer to above Table 1 – Coarse Class). Additionally, odds for G4 (the baseline group) are 183/12605 =1.45%. The odds ratio is the ratio of these two numbers 4.46%/1.45% = 3.07. Now, take the natural log of 3.07 i.e. ln(3.07) = 1.123 – this is our c for G1. Similarly, you could find the coefficient for G2 and G3 as well. Try it with your calculator!
These coefficients are the β values to our original equation and hence the equation will look like the following
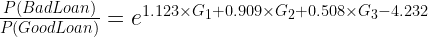
`
Remember, G1, G2 and G3 can only take values of either 0 or 1. Additionally, since they are mutually exclusive when either of them is 1 the remaining will automatically become 0. If you make G1 = 1 the equation will take the following form.

`
Similarly, we could find the estimated value of bad rate for G1

`
This is precisely the value we have observed. Hence, the logistic regression is doing a good job for estimation of bad rate. Great! We have just created our first model.
Sign-off Note
Euler, though blind, showed us the way to come so far! Let me also reveal some more facts about the most beautiful formulae we have discussed at the beginning of this article. In the top five places, you will find two more formulae discovered by Leonhard Euler. That is 3 out of 5 most beautiful formulae. Wow! I guess we need to redefine blind.
To learn more about leonhard Euler watch the following You Tube Video by William Dunham (Video)
Dear Roopam Upadhyay,
Why there is no G4 in your Logistic Regression? Because if you come to the same result as in Logistic Regression with Weight of Evidence, so I think there must be G4 in this Logistic Regression.
One more question, could you explain the use of sample weight in logistic regression (in SAS for exemple). If I make a sample by stratify so sample weight is 1? And if I take a random sample I must calculate the sample weight and input in SAS?
Thank you,
Df
Sorry for a little delay in responding to you questions. The first one first, there are a couple of ways one could answer the absence of G4 in the model. Firstly, if you set G1, G2 and G3 to zero, what you are left with is the probability for G4. Hence G4 is redundant. A more technical reason for this is the same reason why you don’t use all the combinations of dummy variables while performing linear regression.
To answer your second question, sample weights in SAS are provided to tell the program that you have performed balance sampling for your development sample of good and bad. As you may know for the scorecard development one often take all the bads and a sample of goods. Once SAS knows the weight of balanced sample it artificially adjust the weights of regression parameters to mimic the population.
Hope this helped.
Dear Roopam Upadhyay,
Thank you for your quickly reply. As you mentioned here G4 is redundant but when we use WOE and next step is scaling the score, how could you assign a score for G4 attribute?
Regards,
That’s a good question. When you create WOE you transform your groups (categorical or ordinal variables) to ratio scale variables. Now you can run your regression normally without worrying about dummy variables.
Hi Roopam,
I am practicing on Term deposit project on SAS. Most of the steps i have completed like to get WOE and information value….
proc sql;
create table new8 as
select nprevious,count(*) as total_obs,min(previous)as minimum_previous,max(previous)as maximum_previous,
sum(case when y=”yes” then 1 else 0 end)as good,
sum(case when y=”no” then 1 else 0 end) as bad,calculated good/calculated total_obs as pergood,
calculated good/5289 as distgood,calculated bad/39922 as distbad,
log(calculated distbad/calculated distgood) as woe,calculated distbad – calculated distgood as db_dg,
calculated db_dg* calculated woe as contribution
from new1
group by nprevious;
quit;
……….. then after this I performed this step given below:
data new2_1;
set new1;
if nage= 0 then age_woe= -0.53779; else
if nage= 1 then age_woe= 0.25085; else
if nage= 2 then age_woe= 0.2493; else
if nage= 3 then age_woe= 0.33134; else
if nage= 4 then age_woe= 0.27174; else
if nage= 5 then age_woe= 0.14893; else
if nage= 6 then age_woe= 0.10641; else
if nage= 7 then age_woe= 0.10848; else
if nage= 8 then age_woe= -0.03163; else
if nage= 9 then age_woe= -0.53963;
if nday= 0 then day_woe= 0.15573; else
if nday= 1 then day_woe= -0.15435; else
if nday= 2 then day_woe= 0.15793; else
if nday= 3 then day_woe= 0.3409; else
if nday= 4 then day_woe= 0.07231; else
if nday= 5 then day_woe= -0.15655; else
if nday= 6 then day_woe= -0.29775; else
if nday= 7 then day_woe= 0.1444; else
if nday= 8 then day_woe= 0.14226; else
if nday= 9 then day_woe= -0.39466;
if nbalance= 0 then balance_woe= -0.37232; else
if nbalance= 1 then balance_woe= -0.40787; else
if nbalance= 2 then balance_woe= -0.22359; else
if nbalance= 3 then balance_woe= -0.09445; else
if nbalance= 4 then balance_woe= -0.03413; else
if nbalance= 5 then balance_woe= 0.02833; else
if nbalance= 6 then balance_woe= 0.08482; else
if nbalance= 7 then balance_woe= 0.28201; else
if nbalance= 8 then balance_woe= 0.42917; else
if nbalance= 9 then balance_woe= 0.80799;
if nduration= 0 then duration_woe= -1.83857; else
if nduration= 1 then duration_woe= -0.68569; else
if nduration= 2 then duration_woe= -0.18239; else
if nduration= 3 then duration_woe= -0.05863; else
if nduration= 4 then duration_woe= 0.2941; else
if nduration= 5 then duration_woe= 0.59802; else
if nduration= 6 then duration_woe= 1.03615; else
if nduration= 7 then duration_woe= 1.49871; else
if nduration= 8 then duration_woe= 2.47406; else
if nduration= 9 then duration_woe= 4.16833;
if ncampaign= 0 then ncampaign_woe= 0.66039; else
if ncampaign= 1 then ncampaign_woe= 0.29227; else
if ncampaign= 2 then ncampaign_woe= 0.04982; else
if ncampaign= 3 then ncampaign_woe= 0.04882; else
if ncampaign= 6 then ncampaign_woe= -0.25478;
if npday= 0 then npday_woe= 0.09654; else
if npday= 1 then npday_woe= 0.90346;
if nprevious= 0 then nprevious_woe= 0.10428; else
if nprevious= 1 then nprevious_woe= 0.89572;
run;
Now could you please tell me the rest steps to complete this. Thanks
Logistic regression is most appreciated in terms of having a binary dependent variable – in this case bad loan or not bad loan. Coding the equation in the software you use makes it easier to understand because of its binary quality. While regressing it in the form of a ratio is also correct, the appeal of ease of understanding is diminished. Isn’t this the purpose of using a logistic equation base? So we can estimate a binary dependent variable?
Yes that is correct, logistic regression is mostly used for binary dependent variable. However, there is no reasons why you cannot extend the construct to multinominal or ordinal dependent variables. Although, these applications are not as common. If I am getting your question correctly, the usage of logistic regression is not for ease of coding in the software but because for most business problems ratio variables are not possible like the one with the bad and good loans.
Hi Roopam,
I like the way you have simplified modelling for people like me. I would seek your advice on the coarse classification.
How do we know what are the most optimal bins?
I know we can split it in declies/ventile and then plot and see- but this method is bound to give me “multiples” of tens as buckets. For example- let me rephrase the question to:
In the above age class 27-30, there could have been a real split of 28-28 and 29-30 too? So how do we know what’s the most optimal split?
Many thanks
Ashu
Hi Ashu: Thanks for the kind words! That is a good question. In coarse classing, the ideal bins depends on identifying points with sudden change of bad rates. I must also say. there are several subjective calls analysts take while defining bin widths. One has to use both business knowledge and careful eyeballing (simultaneously for both bad rate and counts) to create coarse classes manually from fine classes. You could also code an automated rolling window algorithm or decision trees to identify points of inflections to create coarse classes (like SAS Enterprise Miner). In both manual and automated methods, one can never be sure if they have created the perfect coarse classes. However, for most practical purposes this little bit of imperfection is acceptable.Hope this helped.
Now I got it my answer here. Thank you very much.
Hi Roopam,
Can you please explain why do we need a baseline group in logistic regression model?
I guess it gives us a relative look between coarse classes we created.
And how did you set G4 as your baseline? Why not any other coarse classes?
Thank you.
Hi Hande,
Let me try to explain the reason why we can’t have all the attributes of a categorical variable (all dummy variables) in the model. The root of this problem is with the mechanism in which we solve regression equations using linear algebra or matrix operations. Having all the attributes of a categorical variable in a matrix will make it unsolvable because all the components of this matrix could be represented as linear combinations of other components. In our example, if an observation is not G1, or G2, or G3 then that observation is G4 (hence G4 could be represented as a linear combination G1, G2 and G3). I suggest, you read more about dummy variables to understand this better.
You could have set either group as baseline. I chose G4 but there is no reason for this. One could set any group as baseline it won’t make any difference in the final results, just the regression equation will get modified according to the new baseline.
Hope this helped.
Thank you Roopam.
If we include G1,G2,G3,G4 and the constant there will be five unknowns and four equations, hence no solution. So you set G4 as the constant (since all coarse groups are mutually exclusive) and once you’ve calculated it, you use it to find other groups’ betas using the ln(x) properties.
Thanks Hande, I like your explanation.
Good article to learn logistic regression
Hei,
I know this thread is very old, but I was wondering how the constant is calculated.
Constant is part of the result for logistic regression
Hi,
This is the best tutorial i had seen….Really awesome
Hei Roopam,
Thank you for the reply, I am trying to recreate the exact same example in excel in order to gain deeper insight into how I can create a logstics modell.
I do have a statistical tool that can perform all the things you have explained, which i merley tweak in order to obtan the most optimal modell.
I would like to do this in Excel just to gain deeper insight and understanding of how every single thing is calculated. I do know tha tthe constant is part of the result for a logistics regression, but what is the equation for calculating the constant after all the beta coefficients have been calculated, or am I asking a stupid question atm?
/James
For this I suggest you use Excel Solver to optimize (minimize error) with the given data. Logistic regression parameters are usually calculated using maximum likelihood hence if you really want to make logistic regression model on Excel try Solver. Otherwise, R is a much better choice.
Dear Roopam,
How did you do a logical regression between age groups and bad rates?
I’m a little confused because age groups are names rather than numerical values.
Byeong
Sorry, I forgot to clarify if bad rates refer to the % bad loans.
Byeong
Hi Byeong,
Age group is a categorical variable (ordinal to be precise). Categorical variables are used the same way in logistic regression as in multiple linear regression using dummy variables.I suggest you read about linear regression with dummy variables .
Hi,
I would like to apply logistic regression, but I don’t know from where I can get banking data.
Could you give me any help.
Thank you
Try this : German Credit Data
Thank you very much for your help,
But, could I also have bi-variate logistic application on banking data,
Thank you again for your time and reply,
I can’t understand why in the German.data there 20 variables and in the numeric.data we have 24?
We should have the same, non?
Can we have negative scores in different buckets for a particular variable? Also can we have an overall negative credit score if we are using 600 and 620 for scaling.
Hello, here is a little mistake in formula: The odds (bad loans/good loans) for G1 are 206/4821
There is 4821 but should be 4615 (good loans). The answer is right so I am sure it is a misprint, but it can be confused for beginners.
Thank you for your blog
Fixed it. Thanks for letting me know.
In case of a rolling window if any of the window has very high event rate as compared to others because of one month being higher than rest of the month ,can we leave out that month while choosing the window since this would inflate the event rate.
dear Sir’
I would like to ask how will I arrange my data to perform binary logistic regression? these are all in likert scale and my dependent variable are in 0 and 1? pls help
I have 6 predictors which are answered in likert scale as 1- 5). After I got the weighted average per rating I run this in minitab together with the binary data as my dependent variable. but when run this is the error shown in the computer. Please reply
Binary Logistic Regression: DV versus SO; CP; FP; CFI; DLS
* ERROR * The model could not be fit. Maximum likelihood estimates of parameters may not
exist due to quasi-complete separation of data points. Please refer to help for more
information about quasi-complete separation.
Dear Roopam,
I am trying to replicate your results. Although I do get the same number for the coefficients the z-statistics are nowhere near. Note that I have verified this with various statistical softwares such as MATLAB, EXCEL ( I have a logit VBA function in EXCEL) and R. So I am pretty sure it is not a software issue rather an input issue.
Because the devil lies in the details could you please tell me exactly (or even post as a separate EXCEL file) how my dependent and independent variables look like? i.e. how many observations they have etc.
If I understood correctly the dependent variables (Y) is the percentage of bad loans divided by the percentage of good loans. The independent variables (X) are just 0 and 1 depending if the observation belongs to group 1 , 2 or 3. However, if we run this logistic regression we can do it in two different ways (either run it on 13 observations or use the coarse data which only have 4 observations). If I understood correcly you use only coarse data so effectively you have 4 observations. Both methods give the same coefficient estimates but not the same z statistics. Both both methods do not give the z-statistics you have computed.
Also please note that I only get the same coefficient estimates if my dependent variable is my percentage of bad loans not the percentage of bad loans divided by the percentage of good loans.
I hope this email is clear. If I have confused you please let me know and I will try and make my question more precise.
Thank you
Panagiotis Ballis-Papanastasiou
hello i need an example of logistic regression using real data