
The Olympics – by Roopam
Welcome back to our retail case study example for marketing analytics. In the previous 8 parts, we have covered some of the key tasks of data science such as:
In this part, we will learn about estimation through the mother of all models – multiple linear regression. A sound understanding of regression analysis and modeling provides a solid foundation for analysts to gain deeper understanding of virtually every other modeling technique like neural networks, logistic regression, etc. But before moving to regression, let’s try to put some fundamental ideas behind statistics in perspective by using the most followed event of the summer Olympics..
100 Meters Sprint
The first Olympic games I followed was in 1988 held in Seoul, South Korea. That was the same Olympics where Ben Johnson broke the then world record for 100 meters sprint by completing the race in 9.79 seconds. Later, Johnson was tested positive for consumption of performance enhancing drugs. He was disqualified from the race, and stripped of his gold medal. For a sporting event that lasts just close to 10 seconds, 100 meters sprint is arguably the most followed event of the summer Olympics. In 2012 Olympics, Usain Bolt created a new record by finishing the race in 9.63 seconds. The following is the list of medal holders for 2012 Olympics (source: Wikipedia)
| Rank | Lane | Name | Nationality | Reaction | Result |
|---|---|---|---|---|---|
| 7 | Usain Bolt | 0.165 | 9.63 | ||
| 5 | Yohan Blake | 0.179 | 9.75 | ||
| 6 | Justin Gatlin | 0.178 | 9.79 |
Usain Bolt is widely regarded as the fasted man in the world. However, I must say that…
You Can Beat Usain Bolt in 100 Meters Sprint
Before I explain how, let us go back to the medal holders of 2012 Olympics. For Instance, if we make Usain Bolt run the 100 meters race one thousand times, he will finish each race with a different timing, mostly close to his record time in the Olympics. The same is also true for the other medal holders Yohan Blake, and Justin Gatlin. For argument’s sake, let’s assume the following distributions for race completion time for the three medal holders. The following distributions are all normal or Gaussian distributions. Normal distribution is a good assumption for most natural phenomena like running speed of humans.

Using the above distributions the gold medal will still stay with Usain Bolt as the most likely case. However, there are still cases in which either sprinter can win the gold medal. This, according to me, is the foundation of statistical thinking.
Now coming back to our title for this section, if you compete with Usain Bolt Googolplex number of times then there is still a likely case that you will win at least one race against the fastest man in the world. Yay!
| Law of large numbers: |
| Googol is 10100 : this is a really large number. Googol is also the inspiration behind the name for Google (search engine) – yes the smart founders of Google misspelled it. |
| Googolplex is 10Googol : this is unfathomably large number. Google’s corporate head quarters in California is called Googleplex. |
Regression Analysis – Retail Case Study Example
Now let’s come back to our case study example where you are the Chief Analytics Officer & Business Strategy Head at an online shopping store called DresSMart Inc. set the following two objectives:
Objective 1: Improve the conversion rate of the campaigns i.e. number of customer buying products from the marketing product catalog.
Objective 2: Improve the profit generated through the converted customers
You have achieved the first objective in the previous few parts of this case study example. The classification models (Part 5, Part 6, Part 7 & Part 8) were used to estimate the propensities of customers to respond to campaigns. This leaves you with the second objective to estimate the expected profit generated from each customer if he/she responds to the campaign. This is a classical regression problem. To develop a regression model you will use the data for 4200 customers, out of hundred thousand solicited customers, those have responded to the previous campaigns. All these 4200 customers live in different locations that can be grouped into the following three categories
- Large Cities
- Mid-Sized Cities
- Small Towns
Incidentally, these customers are evenly divided into these three categories with 1400 customers in each group. The first thing you checked is the average value of profit generated from these three categories of cities. As you could see in the figure below average values for profits are different for these categories. Keep these average values in mind, they will come handy when we will develop our regression model.

Now the second question is if these average values for profits are significantly different or not. This question is answered using the location category wise distributions of all the 4200 customers. The above figure shows a representation of these distributions (towards right). For our original data, the following are the location category wise density distribution for all the 4200 customers. Notice, profit is negative for some cases in this distribution because of returned products by customer, and other losses.

There are a couple of intuitive insights in the above plots:
- The large cities have a bigger average value for profits than the others because of higher earning capacity and disposable income for residents of the large metropolitan cities.
- The large cities also have a wider distribution of profit than other two categories because of greater socio-economic diversity for the large metropolitan cities.
Keeping the above insights in mind, let’s create our simple regression model with these categories as the predictor variables. The following is the results for our regression model:
| Coefficients: | Estimate | Std. Error | t value | Pr(>|t|) |
| Intercept | 46 | 0.4691 | 98.06 | <2e-16 |
| Mid Sized Cities | 8 | 0.6635 | 12.06 | <2e-16 |
| Large Cities | 22 | 0.6635 | 33.16 | <2e-16 |
| Multiple R-squared: | 0.2069 | |||
| Adjusted R-squared: | 0.2065 | |||
| F-statistic (P Value) | 2.20E-16 |
The following is the linear equation for this regression model

Notice, that the model just has mid-sized and larger cities as the predictor variables. The information about small towns is absorbed in the intercept part. Also, these predictor variables are dummy variables hence they can have 0 or 1 as the only possible choices for values. For instance, if the location is a small town then mid-sized cities = 0, and large cities=0 hence the profit is:

Recall the above average figures, this is the same average value for small towns. Now, if the location is a mid-sized city then
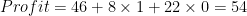
Again this is the same as the average value for mid-sized cities. Finally, the estimated profit through the resident customer of a large city is:
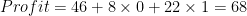
Now the next question is : how good is this model? For this we will have to scroll up to the regression model results and look at the following three things:
- P values for individual coefficients: Look at the right most column for the coefficients – the value is really small <2e-16 this means that the model is almost 100% certain that the coefficients will not become zero. This is similar to your chances of beating Usain Bolt i.e. extremely low but not zero.
- Adjusted R-squared value: for our model which is 0.2065. This means that just the category of location explains about 20% of the variation in profit. This is not bad for a single categorical variable if we will keep adding more significant variables to the above model the value of Adjusted R -squared will keep increasing.
- F-Statistics: Again the p-value here is really small i.e. 2.20E-16. This means the model has very low chance of being random similar to your chances of randomly beating Usain Bolt.
Sign-off Note
The following statements summarize the essential ideas behind the Olympic games. The most important thing in the Olympic Games is not to win but to take part. The essential thing is not to have conquered but to have fought well.
So go out, play well, and most importantly enjoy even if the opponent is the fastest man on the planet. See you soon with a new post.
very intuitive and one of the best effort to explain data science
Great article.
Can you please elaborate bit more on how dummy variables will be assigned? I think we need to create two dummy variables one for mid-size city and other for large-size city. The values for small town is removed to avoid dummy variable trap. The removed dummy then becomes the base category against which the other categories are compared. In this case it is included part of intercept. Is this understanding right?
Yes Reva, your understanding is right. The intercept in this case is the average value for small towns. In case there were more than one dummy variables then the intercept will absorb the information for all the baseline values for these dummy variables.
Why is the chance to beat Usain Bolt one in a Googolplex number of times? And how can this be connected to the p value which is nowhere as close to even Googol at 2.20E-16. Could you please explain this concept in more detail Roopam?
R uses this notation (<2.20E-16) to denote very small probabilities - this is because of the computational limitation. Notice the 'less than' sign. This is kind of similar to -infinity in the mathematical terms. It is essentially a tiny probability. But for all practical purposes, it doesn't matter how small it is.
Thank you Roopam 🙂 this is super useful
Roopam
Any chance u cld share the code.
Thanks
Sai
Hello Roopam,
Your blog is one of the best resources online and is helping me a lot. I am preparing for my interviews and your blog is a gold mine of information for case studies/projects etc.
Could you please provide the dataset and the code for this case study.
Thanks,
Anand
When I clck on the link for past 2 or past 3 etc I am directed to you main page.
how do i reach to those page. 🙁