
Entropy : from order to disorder – by Roopam
This article is a continuation of the retail case study example we have been working on for the last few weeks. You can find the previous parts of the case study example at the following links:
Part 1: Introduction
Part 2: Problem Definition
Part 3: EDA
Part 4: Association Analysis
Part 5: Decision Tree (CART)
If you recall from the previous article, the CART algorithm produces decision trees with just binary child nodes. In this article, we will learn another algorithm to produce multiple child nodes decision trees. There are several ways to achieve this objective such as CHAID (CHi-squared Automatic Interaction Detector). Here, we will learn about the c4.5 algorithm to produce multiple child nodes decision trees. Since it uses a concept very close to my heart:
Entropy
In high school, we were taught the first law of thermodynamics about conservation of energy. It says:
Energy can neither be created nor destroyed, or in other words the total energy for the Universe is constant.
The first reaction from most students after learning this fact was : why bother saving electricity, and fuel? If the total energy of the universe is constant and conserved then we have an infinite amount of energy for usage that will never be destroyed.
The second law of thermodynamics, however, demolishes this comfort about wasting power. Entropy is at the root of the second law of thermodynamics. Entropy is the measure of disorder or randomness in the Universe. The general direction of the Universe is from order to disorder or towards higher randomness. The second law states that:
Total entropy or overall disorder / randomness of the Universe is always increasing.
OK, let’s take an example to understand this better. When you use fuel to run your car, a perfectly ordered petrol (compact energy) is converted/dissipated to disordered forms of energy like heat, sound, vibrations etc. The work is generated in the process to run the engine of the car. The more disordered or random the energy is the harder/impossible it is to extract purposeful work out of it. So I guess, we care about work and not energy. In other words, higher the entropy or randomness of a system the harder it is to convert it to meaningful work. Physicists define the entropy of a system with the following formula:

Entropy is also at the heart of information theory. It took the ingenuity of Claude Shannon, the father of information theory, to see the links between thermodynamics and information. He proposed the following definition of entropy to measure randomness within a given message.
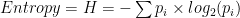
For instance entropy (randomness) of a fair coin, with the equal chance of heads & tails, is 1 bit (as calculated below). Notice, the unit of entropy in information theory is a bit as coined by Claude Shannon. This same unit is used as the fundamental unit of computer storage.
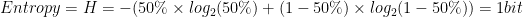
We will use the same formula for entropy to create decision tree and decipher information within the data.
Retail Case Study Example – Decision Tree (Entropy : C4.5 Algorithm)
Back to our retail case study Example, where you are the Chief Analytics Officer & Business Strategy Head at an online shopping store called DresSMart Inc. that specializes in apparel and clothing. In this case, your effort is to improve a future campaign’s performance. To meet this objective, you are analyzing data from an earlier campaign where direct mailing product catalogs were sent to one hundred thousand customers from the complete customer base of over a couple of million customers. The overall response rate for this campaign was 4.2%.
You have divided the total hundred thousand solicited customers into three categories based on their past 3 months activities before the campaign. This is the same table we have used in the previous article to create the decision tree using the CART algorithm.
| Activity in the Last Quarter | Number of Solicited Customers | Campaign Results | Success Rate | |
| Responded (r) | Not Responded (nr) | |||
| low | 40000 | 720 | 39280 | 1.8% |
| medium | 30000 | 1380 | 28620 | 4.6% |
| high | 30000 | 2100 | 27900 | 7.0% |
The following is the binary node tree we have generated through the CART in the previous article.

Decision Tree The CART
Let us see if we can produce a better tree using entropy or the c4.5 algorithm. Since the c4.5 algorithm is capable of producing multiple node decision trees, hence we will have one additional possibility of a tree (with 3 nodes – low; medium; high). This is in addition to the binary trees explored in the previous article.
The way the c4.5 works is it compares the entropy of all the possible trees with the original data (baseline data). Then it chooses the tree with maximum information gain i.e. difference of entropies:

Hence we need to first calculate the baseline entropy of data with 4.2% conversion (4200 conversions out of 100,000 solicited customers). Notice in the second term 95.8% (=100%-4.2%) is the percentage of non-converted customers.
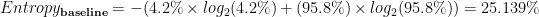
This is the same value we have calculated at the bottom-most row of the following table for total entropy.
| Child Nodes | Number of customers | Number of customers responded | % responded | Individual Node entropy | Total Entropy | Information Gain |
| low | 40000 | 720 | 1.8% | 0.130059 | 24.255% | 0.88% |
| medium | 30000 | 1380 | 4.6% | 0.269156 | ||
| high | 30000 | 2100 | 7.0% | 0.365924 | ||
| low | 40000 | 720 | 1.8% | 0.130059 | 24.370% | 0.77% |
| medium + high | 60000 | 3480 | 5.8% | 0.319454 | ||
| low+ medium | 70000 | 2100 | 3.0% | 0.194392 | 24.585% | 0.55% |
| high | 30000 | 2100 | 7.0% | 0.365924 | ||
| low + high | 70000 | 2820 | 4.0% | 0.242292 | 25.127% | 0.01% |
| medium | 30000 | 1380 | 4.6% | 0.269156 | ||
| Total | 100000 | 4200 | 4.2% | 0.25139 | 25.139% |
Now let us try to find the entropy of the tree by calculating entropies of individual components of the first tree (with 3 nodes – low; medium; high)

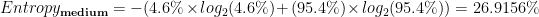

Now, the total entropy of this tree is just the weighted sum of all its components. Here, the weights are the number of customers in a node divided by the total number of customers e.g. 40,000/100,000 = 0.4 for the first node.

Finally, we need to find the value of information gain i.e.

Incidentally, information gain for the tree with three nodes is the highest as compared to other trees (see the table above). Hence, the c4.5 algorithm using entropy will create the following decision tree:

C4.5 Decision Tree using Entropy
Sign-off Note
How cool is entropy! Yes, I admit I love physics. However, this connection of thermodynamics with information still gives me goose bumps. The idea is that information removes uncertainty or randomness in the system. Hence, using information one can take the path from disorder to order! Yes, the Universe is destined to move toward disorder or randomness, but in small pockets, we can still use information to produce order.
| If you are keen on learning deeper links between thermodynamics & information theory then watch the following two-part documentary by the BBC: – Order and disorder (Link) |
See you soon with the next article.
Quite interesting.
This is really interesting (sage of physics in analytics)………..thank you for posting such a nice article
🙂
very well explained Roopam!
the way u explain analytics is awesome …….thank you
IIT-B rocks! This is awesomely put together! Cheers!
This has to be the best explanation of decision trees…thanks a lot
Brilliant explanation. Most of the statisticians, who i have talked to, only provide formulae and definitions but lack the basic understanding of analytics (they know the how but not the why). Your blog is by far the best analytics blog i have ever read. The analogies, which you provide, help me visualize the problem and techniques.
A big kudos for your effort
Hi Roopam,
Can you help me in understanding the result I am getting after applying randomforset:
Call:
randomForest(formula = myFormula, data = tree)
Type of random forest: classification
Number of trees: 500
No. of variables tried at each split: 3
OOB estimate of error rate: 46.93%
Confusion matrix:
F M class.error
F 1040 992 0.4881890
M 960 1167 0.4513399
Thanks
Roopam,
The entropy (low, medium, high etc) in the above table is different from what I tried to calculate.
> x1=c(4.2,1.8,4.6,7,1.8,5.8,3,7,4,4.6)
> y1=-( (x1/100*log(x1/100,2))+ ((100-x1)/100*log((100-x1)/100,2)) )
> x1
[1] 4.2 1.8 4.6 7.0 1.8 5.8 3.0 7.0 4.0 4.6
> y1
[1] 0.2513881 0.1300588 0.2691559 0.3659237 0.1300588 0.3194540 0.1943919
[8] 0.3659237 0.2422922 0.2691559
>
Am I missing something ?
Please help.
Thanks
Hey Raj,
Sorry for the delayed response. By the way, your calculation is correct. I took a shortcut in my calculations of multiplying weights of each node in a single step i.e. 0.1300588 * 0.4. This caused all the confusion. I have made the corrections in the article now. Thanks for pointing this out.
Cheers,
Hi roopam,
Great articles!
About the numbers, I thing that raj is right.
Thank you very much Roopam for your effort to simplify concepts and make them easy to absorb.
Sir, Really want to thank you…Your way of explaining things is really wonderful…