
Model Selection – by Roopam
Model Selection
This is a continuation of our retail case study example for campaign and marketing analytics. In the previous two parts, we discussed a couple of decision tree algorithms (CART and C4.5) for classification. Recall a previous case study example on banking and risk management where we discussed logistic regression which is another approach to solving classification problems. Additionally, there are several other statistical and machine learning algorithms that are equally powerful for classification tasks such as:
- Support Vector Machines
- Random Forest
- Artificial Neural Networks
- Discriminant analysis
- Boosting
- Naïve Bayes Classifiers
This list is definitely not complete but covers some of the commonly used approaches. We will discuss all these approaches in later articles on YOU CANalytics. Now the question is: why there are so many different approaches to solving the same problem? A more important question which everybody asks is: which one approach of these is the best? The answer to the second question is none! Yes, the best approach depends on the kind of data you are working with, and since data come in all shapes and sizes hence you can’t have one best approach for all problems. Hence, development of models with different approaches, and the best model selection for your data is an important exercise in data science and analytics. In this article, we will discuss the factors that influence the process of model selection. However, before that let us quickly examine some of the tasks data scientists perform, as this will help us when we will make our transition to next parts of this case study example.
Tasks for Data Science
Primarily, tasks that data scientists perform could be grouped into the following six broad categories as displayed below. Please note that even the modern data science tasks such as web & social media analytics, text mining, image analytics, and sound pattern detection are some the used cases of these six broad categories.
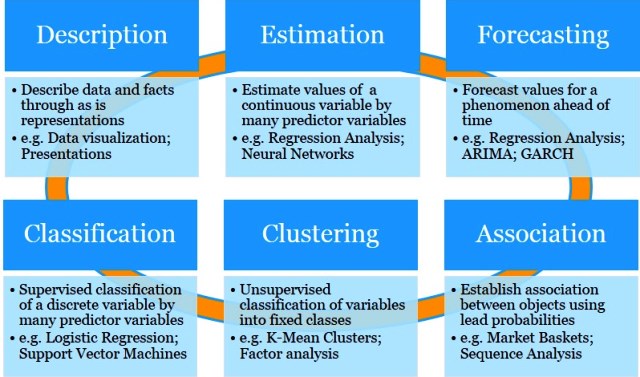
Data Science Tasks – by Roopam
As you might have noticed, in this case study, we have so far performed 3 tasks from the above list i.e. ‘Description’ (exploratory data analysis), ‘Association’ (association analysis), and ‘Classification’ (decision trees: CART and C4.5). I must say, exploratory data analysis (EDA) is an integral part of every data science project. EDA is a crucial exercise that drives predictive models in the right direction.
In the last few parts of this case study, we will do some ‘Estimation’ (i.e. regression analysis to estimate revenue generated by customers through campaigns). Let’s go back to model selection for our classification problem.
Model Selection – Retail Case Study Example
Back to our retail case study example, where you are the Chief Analytics Officer & Business Strategy Head at an online shopping store called DresSMart Inc. that specializes in apparel and clothing. Through your rigorous exploratory data analysis you have found several factors that play crucial roles in marketing campaigns’ response for customers, some of these factors are:
- Recency: # recent visits to the company’s website and purchases
- Frequency: time lag between purchases in the last 6 months
- Payment mode used: cash on delivery, credit card, internet banking etc.
- Marketing data aggregator’s: life-stage segmentations (i.e. luxury buffs, up-scale ageing, first-time earners etc.)
- Last year’s expenditure trend: amount spent last year
- Coupon usage pattern of customer
You have tried several multivariate models mentioned above (i.e. logistic regression, SVM, decision trees etc.) to model customers’ behaviour and generate purchase propensity scores. The choice of right model selection depends on the following 2 factors i.e.
- Predictive power of models
- Business & operations integration
1 Predictive power of models
The first factor for model selection is the overall predictive power that the model has in comparison to other models. For this classification problem, the area under receiver operating curve (AUROC) is possibly the best way to assess the predictive power of models (read more about AUROC). Sometimes people also use Gini coefficient for assessing predictive power of models, Gini is another variant of AUROC and mathematically represented as:

Area Under ROC for Different Models
In the adjacent plot, AUROC is displayed for artificial neural networks, logistic regression, and CART decision tree. Notice, the perfect model curve (in green) here is with 100% predictive power, and random model (in red) represents prediction through the flip of a coin. The AUROC values for the test sample for the 3 models are:
| Model | AUROC |
| Decision Tree | 72% |
| Logistic Regression | 76% |
| Artificial Neural Networks | 77% |
Decision tree here is performing much below the other two models. This is often the case with decision trees, but they are still very useful and popular because of their highly intuitive and easy-to-explain solutions. Artificial neural networks are performing a notch above logistic regression in this case with a slightly higher area under ROC. Hence by the first criteria, artificial neural networks offer the best model among the 3 models.
2 Business & operations integration:
This aspect of model selection is equally important as the above factor if not more. The model selection must be based on productization of the model for business usage in the long run. The following factors are useful to keep in mind at the beginning of modeling process:
1) Consistent availability of data for all predictor variables: many times models are developed by predictor variables that are hard to procure regularly and consistently. Keeping such variables in the model is not advisable even if they contribute to high predictive power. This is especially true for third party data which is purchased once in a while.
2) The model should be simple enough to calibrate: this factor is really important if the model will be used for a long duration i.e. more than 2 years. Certain models are relatively easy to calibrate or alter according to changes in market environment. This way analysts don’t need to rebuild a new model every so often.
3) Integration with information system and business process: the goal of any model is to integrate well with IT systems used by business users. Analysts must think of productionization of the model for business process integration at the beginning of the project to avoid unnecessary rework at the completion of the project.
4) Business users’ commitment for regular usage of models: data science is not just an intellectual exercise. The most important aspect of data science’s success is the generation of business value through actionable insights, and business users’ commitment to act on these insights. This commitment by business users come from their involvement in, and understanding of model building process. Data scientists need to communicate well with business users throughout to gain their trust.
Sign-off Note
In this article, we have noticed that artificial neural networks performed slightly better than logistic regression and decision tree algorithms for our dataset. We will discuss neural networks in the next article before continuing with the next part of this case study i.e. estimations through regression. See you soon!
Its interesting your page
Great article on model selection. I was wondering whether you also considered SVM as one of the classification techniques for the retail case study.( and subsequent comparison of its predictive power with other models).Also will be great if the dataset could be shared.
Nice article. I’ve seen similar results in both retail and credit card/financial services models. I think this explains why neural nets despite a marginal advantage over regression have failed to take over the world and why the choice often comes down to regression vs trees. The advantage of an easily defined consistent group that marketing teams and creatives can build a great offer around sometimes outweighs the 5% difference but sometimes not, the grey area where data science joins data art.
Hi,
How do you identify customers who responded or did not respond to a campaign in the past?. Assume a campaign starts from 1Jan 2014 to 31Feb 2014, the customers who made purchases while the campaign was ongoing are considered ‘responded’?
Thanks
Usually, it is advisable to create a detailed process to identifying customers acquired through the campaigns with absolute certainty before the campaigns. This involves separate landing pages /micro-sites, short codes, discount coupons, and many other strategies. However, in absence of a process one has to rely on proxies like the one you have mentioned (this is not a good idea in the long run).
Hello Roopam,
Hope you are doing great!
i have been following you through different published articles- you are really helping a lot many analytics enthusiasts like me.
I would like to know more on the “productization of the model for business”- e.g. i have created a predictive model and would like to productized it such that it would be ready for Go-to-market service offering.
Thanks in anticipation.
Regards,
Hi Roopam,
Nice article.
One question. Let’s say I want to include macroeconomic variables in my study to predict Prob of Default ( PD). In that case would decision tree work? If not why?
Thanks!
Yes, there is no reason to believe why it will not work similar to any other dataset.
Hi Roopam,
Can you please elaborate more on this point “The model should be simple enough to calibrate”. Do you mean hypertuning the model should be easy or is it something else?
Hi Roopam,
Can you please explain how exactly do we come to know that we want to use Estimation or Forecasting? For example , I am trying to predict sales. If I have data from past 3 years, I can use Forecasting and if I have some independent variables, I can use Estimation. If I have both, what is more recommended? Is there a suggested way?
Thanks.
This post will answer your question.
http://ucanalytics.com/blogs/how-effective-is-my-marketing-budget-regression-with-arima-errors-arimax-case-study-example-part-5/
Read the complete case study here to get a complete understanding: http://ucanalytics.com/blogs/category/manufacturing-case-study-example/