
The Night Sky & Cluster Analysis- by Roopam
Galaxies and Cluster Analysis
I live in Mumbai (Bombay), the financial capital of India and one of the largest cities in the world. One of the problems of living in a large city is that you rarely see stars in the night sky. The limited sky one can see through the skyscrapers is smeared with light pollution and it is difficult to sight stars if any. One of the best night skies I have ever seen in my life was at Saint George Island on Gulf of Mexico, Florida. On a pitch-dark night during Floridian winters, one could see more than a million stars in the gorgeous night sky. It is a wonderful sight! My fascination for sky and stars is a possible reason for my fascination for physics. As I have mentioned earlier I have done my masters in physics and am ever curious about astrophysics and the origin of the universe. Let us try to understand the enormousness of the universe we can only fractionally see in the night sky.
Our planet, the earth, may seem like everything to us. However, we know it is just one of the nine (now eight) revolving planets around the sun. The sun is yet another star among around 200 billion stars in the galaxy Milky Way – the place where the sun and the earth reside. This is already enormous but to make it unfathomable, the universe has more than 200 billion galaxies. Using this one could approximate the number of stars in the universe i.e. ~ 4X1022 (from 200 billion X 200 billion, obviously these numbers are a gross approximation). I am happy we can see more than a million stars in a clear night sky, even if it is just a tiny fraction of the actual number of stars. Now, we have the following two questions to answer

Galaxies & Cluster Analysis
1) What are galaxies?
2) What is the relationship between galaxies and the title of this post (cluster analysis / customer segmentation)?
Galaxies are clusters of stars, gas, dust, planets and interstellar clouds. Usually, galaxies are spiral or elliptical in shape (shown in the picture from Wikipedia). The galaxies are separated from neighboring galaxies in three-dimensional space. Enormous black holes are often at the center of most galaxies. These black holes are the binding force providing distinct shapes to the galaxies.
As we will discuss cluster analysis in the next section, you will find striking similarities between galaxies and cluster analysis. As the galaxies are formed in three-dimensional space, cluster analysis is a multivariate analysis performed in n-dimensional space.
Note – keep the concept of black holes at the center of the galaxies in mind. We will use a similar concept of the centroid for cluster analysis really soon.
Cluster Analysis – Telecom Case Study Example
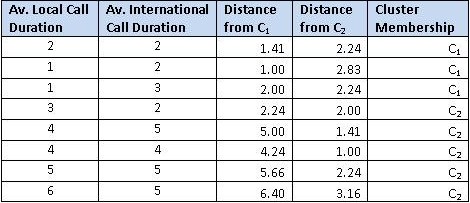
You are head of customer insights and marketing at a telecom company, ConnectFast Inc. You realize that not every customer is similar and you need to have different strategies to attract different customers. You appreciate the power of customer segmentation to deliver superior results with optimized cost. You are also aware of unsupervised learning techniques such as cluster analysis to create customer segments. To brush up your skills with cluster analysis, you have selected a sample of eight customers with their average call duration (both locally and internationally). The following is the data:

To get a feel for this, you have plotted the data with average international call duration on the x-axis and average local call duration on the y-axis. The following is the plot:

Note – this is similar to the cluster of stars in the night sky (here, stars are replaced with customers). Additionally, instead of a three-dimensional space we have a two-dimensional plane with average local and international call duration on the x-axis and y-axis. Now, like galaxies the task is to find the location of black holes; in cluster analysis, they are called centroids. To locate the centroids, we start with assigning random points for the location of centroids.
Euclidian Distance to find Cluster Centroids
In this case, two centroids (C1 & C2) are randomly placed at the coordinates (1, 1) and (3, 4). Why did we choose two centroids? For this problem, visual estimation of scattered plot above informs us that are two clusters. However, we will notice in a later part of this series, this question may not have such a straightforward answer for larger data sets.
Now, we will measure the distance between two centroids (C1 & C2) and all the data points on the above-scattered plot using Euclidean measure. Euclidean distance is measured through the following formula
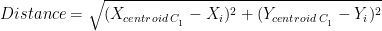
Columns 3 and 4 (i.e. Distance from C1 and C2) are measured using the same formula. For instance, for the first customer
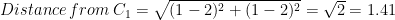
You could measure all the other values similarly. Additionally, cluster membership (last column) is assigned using the closeness to clusters (C1 and C2). The first customer is closer to centroid 1 (1.41 in comparison to 2.24) hence is assigned membership C1.
The following is the scatter plot with cluster centroids C1 and C2 (displayed with blue and orange diamond shapes). The customers are have marked with the color of centroids basis their closeness to the centroids.

As we have randomly assigned the centroids, the second step is to move them iteratively. The new position of the centroid is measured by taking the average of member points for the centroid. For the first centroid, customers 1, 2 and 3 are members. Hence, the new x-axis position for the centroid C1 is the average value for x-axis for these customers i.e. (2+1+1)/3 = 1.33. We will get the new coordinates for C1 equal to (1.33, 2.33) and C2 equal to (4.4, 4.2). The new plot is shown below:

Finally, one more final iteration will take the centroids at the center of the clusters. As displayed below:

The positions for our black holes (cluster centroids) in this case turned out to be C1 (1.75, 2.25) and C2(4.75, 4.75). The two clusters above are like two galaxies separated in space from each other.
Sign-off Note
To me, the number of galaxies (~200 billion) and the number of stars (~4X1022) rationalize the human position in the universe. If humans act separately from the universe and nature, mathematically they are insignificant. However, when we are one with this great creation, the Sanskrit phrase – Aham Bramhasmi (pronounced as ah-HUM brah-MAHS-mee) – sums it up. It means ‘I am Brahma (The creator of the universe)’ & ‘I am the universe’. The creator and creation are one and boundless.
See you soon with more on cluster analysis and the telecom case.
one more final iteration will take the centroids at the center of the clusters C1 (1.75, 2.25) and C2(4.75, 4.75), how? what is the number of iterations? how choose the best one of generated clusters after all iterations?
The reason C1 (1.75, 2.25) and C2 (4.75, 4.75) are the final cluster centers is because any further iteration won’t move the position of C1 & C2. I recommend you try one more iteration (i.e. calculation) on your calculator or excel and see the results for yourself.
The number of iterations depends on the data set, here the iteration termination criteria is when the cluster centroids stop moving i.e. C1(next) = C1(previous). A more applied way of doing this is when C1(next) – C1(previous) = e (a very small number such as 0.001).
For our simple data set we have satisfied the above condition in just 2 iterations. However, it takes a few thousand iterations to satisfy the above condition for most data sets for practical purposes.
OK. that is clear. thank you a lot.
but, depend on what how we can determine the number of (generated) clusters?
in the example, there are just two clusters;
There are two approaches to finding the number of clusters:
1) Sometimes the number of clusters(groups) are predetermined based on the business use- case and application. ex: you want to group your customers into 4 defined categories- faithful, regular, at risk and not faithful.
2) Optimum number of clusters can also be determined by plotting the elbow curve. The point at which the decrease in intracluster distance to inter-cluster distance ratio is insignificant is chosen
Hi Roopam,
i have work on SAS and Spss and i found spss more easier and give the same result as SAS. Then why so we need to go for sas coding and all. why sas has overcome spss. Is R a good software then SAS to learn, does it make any difference.
Can you explain the case study and your experience wiith some more specific and software results with some dummy variables. In this case u can use Hierarchical cluster and them K-mean for the segmentation.
Hi Anita,
That’s a good question. Yes, I agree SPSS generates the same results as R or SAS and its GUI is easier to learn for new users. However, coding is extremely useful for both repetitive analysis, and large data management – these are common tasks in most business scenarios. Additionally, coding provides extra flexibility for analysis, but this is usually exploited by advanced users. SAS presents a unified platform for data analytics including ETL, SQL queries, data cleansing, analysis, deployment, and model monitoring. I must also say that all these features of SAS can be easily replicated with clever implementation of open source software. However, SAS enjoys a huge early bird advantage. Also, SPSS is equally expensive as SAS, so organizations don’t see much merit in replacing SAS with SPSS. Moreover, this will require additional training for the SAS users employees. However, lately I have noticed a major shift towards usage of R and other open source software because it presents a viable option to replace SAS which creates a massive dent in the company’s P&L.
Hi, Ms Anita
Could you please supply a material about SPSS learning?
Here is one SPSS learning link: https://fhss.byu.edu/SPSS%20Modeler/Forms/AllItems.aspx
Hi Roopam,
Thank a lot for sharing and clearing doubts.I love reading your blogs…Keep sharing
Max how many no of cluster can we take if the data is huge
That’s a million dollar question. In theory, 1 is the minimum number of cluster and the number of observation in data is the maximum number of clusters – neither of which is useful. To arrive at the optimal number of clusters, one has to do several iterations to identify the right number of clusters. It’s an effort intensive activity.
Hi Roopam,
I get the impression you may also be interested in the ‘spiritual world’. Not surprising since you live in India. The sanscrit phrase ‘I am the universe’ is a very interesting one. I was very much surprised by the thought that human consciousness is that which observes the universe, therefore, the universe is alive in you, and not ‘we live in the universe’. Certainly a thought that makes you think. Deepak Chopra explains that one very nicely, I assume you know his work since you are so widely curious about things.
Love your blog!
Hans
Hello, It was very insightful reading these articles which I thinks are very-well structured.
I was wondering if you had any tutorials or steps to follow to process your dataset, determine and calculate centroids and add all that data in one table.
Kind regards,
Thanks.
Try this link http://ucanalytics.com/blogs/category/analytics-challenge/cluster-analysis-analytics-challenge/
Hi Upadhyay,
Really your blog is having real content. Thanks for your efforts.
I want to clarify one thing
How to implement Cluster Analysis when Data set has both Numerical & Categorical, Both are having good weight age in terms of Business & Predicting power.