
Greedy Decision Tree – by Roopam
This article is a continuation of the retail case study example we have been working on for the last few weeks. You can find the previous 4 parts of the case at the following links:
Part 1: Introduction
Part 2: Problem Definition
Part 3: EDA
Part 4: Association Analysis
In this article, we will discuss a type of decision tree called classification and regression tree (CART) to develop a quick & dirty model for the same case study example. But before that let us explore the essence of..
Decision Trees
Let’s accept, we all do this before we pick a slice of pizza from the box: we quickly analyze the size of the piece, and proportions of toppings. In this quick optimization, you mostly look for the biggest slice with the maximum amount of your favorite toppings (and possibly avoid your least favorite ones). Hence, I would rather not call this little boy, shown in the picture, greedy. He is just trying to cut his birthday cake to maximize his preferred taste. The cake has his favorite topping i.e red cherries, and not so favorite green apples in equal proportions (50-50). He needs to make a clean cut with just two strokes of the knife otherwise, the guests at his party won’t appreciate his messy use of the knife. With a complete deftness and using the built-in decision tree in his brain, this boy cuts the perfect piece to savor his taste. Let us have a look at his artistry:

Decision Tree Cake – The CART Algorithm
He started with equal proportions of red and green (50%-50%). Remember, he wanted the most number of reds and least number of greens on his piece. His slice , a quarter of the cake, has 71% reds and 29% greens. Not bad! This is precisely how decision tree algorithms operate. Like the above problem, the CART algorithm tries to cut/split the root node (the full cake) into just two pieces (no more). However, there are other decision tree algorithms we will discuss in the next article, capable of splitting the root node into many more pieces.
I must point out that though we are using discrete data (such as red cherries and green apples) for the decision tree in this article, CART is equally capable of splitting continuous data such as age, distance etc. Let us explore more about CART decision tree algorithm.
Classification and Regression Tree (CART)
I find algorithms extremely fascinating be it Google’s PageRank algorithm, Alan Turing’s cryptography algorithms, or several machine-learning algorithms. To me, algorithms are a mirror of structured thinking expressed through logic. For instance, the CART algorithm is an extension of the process that happened inside the brain of the little boy while splitting his birthday cake. He was trying to cut the largest piece for himself with maximum cherries and least green apples. In this problem he had two objectives:
- Cut the largest piece with a clean cut
- Maximize the number of cherries on this piece while keeping green apples at lowest
The CART decision tree algorithm is an effort to abide with the above two objectives. The following equation is a representation of a combination of the two objectives. Don’t get intimidated by this equation, it is actually quite simple; you will realize it after we will have solved an example in the next segment.
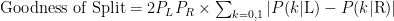
The first term here i.e. 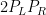 controls the first objective to cut the largest piece. Let me call this first term ‘Ψ(Large Piece)’ because it will remind us of the purpose behind the mathematical equation.
controls the first objective to cut the largest piece. Let me call this first term ‘Ψ(Large Piece)’ because it will remind us of the purpose behind the mathematical equation.
Where as, the second term (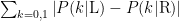 ) controls the second objective. Again like the last equation, let me call this second term ‘Ψ(Pick Cherries)’.
) controls the second objective. Again like the last equation, let me call this second term ‘Ψ(Pick Cherries)’.

For our example, k=0,1 in above equation are 0=green apples & 1=red cherries. Remember, for our case study with marketing campaigns, k=0,1 will become responded (r) and not-responded (nr) customers. Similarly, for our banking case study & credit scoring articles (link) they will become loan defaulters & non-defaulters. However, the philosophy of decision tree and the CART will remain the same for all these examples and much more practical classification problems.
Let me define some important terminologies for the CART decision tree algorithm before explaining the components of the above equation for the goodness of split.

The CART Decision Tree Terminologies
The following is the definition of the components in the above equation for the goodness of split.
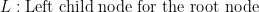
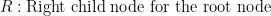



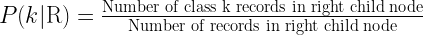
I hope you have realized, the largest value of the product of Ψ(Large Piece) and ‘Ψ(Pick Cherries) called the goodness of split will generate the best decision tree for our purpose. Things will get much clearer when we will solve an example for our retail case study example using CART decision tree.
Retail Case – Decision Tree (CART)
Back to our retail case study example, where you are the Chief Analytics Officer & Business Strategy Head at an online shopping store called DresSMart Inc. that specializes in apparel and clothing. In this case example, your effort is to improve a future campaign’s performance. To meet this objective, you are analyzing data from an earlier campaign where direct mailing product catalogs were sent to hundred thousand customers from the complete customer base of over a couple of million customers. The overall response rate for this campaign was 4.2%.
You have divided the total hundred thousand solicited customers into three categories based on their past 3 months activities before the campaign. The following is the distribution of the same. Here, the success rate is the percentage of customers responded (r) to the campaigns out of total solicited customers.
| Activity in the Last Quarter | Number of Solicited Customers | Campaign Results | Success Rate | |
| Responded (r) | Not Responded (nr) | |||
| low | 40000 | 720 | 39280 | 1.8% |
| medium | 30000 | 1380 | 28620 | 4.6% |
| high | 30000 | 2100 | 27900 | 7.0% |
As you know, CART decision tree algorithm splits the root node into just two child nodes. Hence for this data, CART can form three combinations of binary trees as shown in the table below. We need to figure out which is the best split among these 3 combinations. The results for the same are shown in the table below.
| Left Node | Right Node | PL | PR | P(k|L) = a | P(k|R) = b | Ψ(Large Piece) | Ψ(Pick Cherries) | Goodness of Split |
| 2PLPR | Σ(a-b) |
|||||||
| Low | Medium+High | 0.4 | 0.6 | r: 0.018 | r: 0.058 | 0.48 | 0.080 | 0.0384 |
| nr: 0.982 | nr: 0.942 | |||||||
| Low+Medium | High | 0.7 | 0.3 | r: 0.030 | r: 0.070 | 0.42 | 0.080 | 0.0336 |
| nr: 0.970 | nr: 0.930 | |||||||
| Low+high | Medium | 0.7 | 0.3 | r: 0.040 | r: 0.046 | 0.42 | 0.011 | 0.0048 |
| nr: 0.960 | nr: 0.954 |
Let me help you out with the calculation of each column for the above tree. We will use the first row (i.e left node: Low and right node: Medium+High) for the following calculations and then you could do the rest of the calculations yourself. To start with we have calculated PL and PR in the following way:


Now the calculation for Ψ(Large Piece) is simple as shown below:
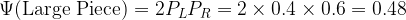
Now, let’s come to the second part of the equation that is Ψ(Pick Cherries). Remember, r represents responded and nr represents not-responded customers for our campaign’s example.
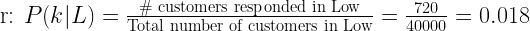

You may want to calculate the other two terms (i.e r: P(k|R), and nr: P(k|R)) yourself before plugging them in the following equation to get the value for Ψ(Pick Cherries).
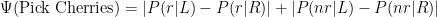

This leaves us with one last calculation for the last column i.e. goodness of split which is:

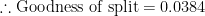
The final task now is to find the maximum value for goodness of split in the last column. This will produce the following decision tree through the CART algorithm with Low on the left node, and Medium+High on the right node.

Decision Tree – The CART Algorithm Final Result
This is an important business insight as well that people with higher activity tend to respond better to campaigns. I agree it was clear from the first table at the top as well, but we have learned the science of creating decision tree using the CART algorithm in the process. This is extremely useful when you are dealing with a large dataset and want to create decision tree through recursive partitioning.
Sign-off Note
OK, next time while choosing that pizza slice, remember the evolutionary decision tree that helps you maximize your chances for the best slice. Once in a while, you may want to leave that best slice for someone else – I bet you will feel equally good!
In the next article, we will extend this concept of binary child node decision tree through the CART algorithm to more than two nodes decision tree through other algorithms. See you soon!
Still digesting this but I think perhaps you made a mistake in the 2nd table, on the bottom row:
Low+high Medium 0.3 0.7
Shouldn’t the 0.3 and the 0.7 the other way round?
Also you say P(k|R) has count of L record counts as the denominator – presumably you meant R? 😉
Thank you for reading this article so carefully! Have corrected the typos.
Hi Roopam ,if i have a variable through which my binary target variable was derived, in that case
the second term of equation will be more than 1(Because P(k=0|L)=|1-0| & P(k=1|R)=|0-1|).
But i guess that is not correct.in that case what will be the calculation for goodness of split for the variable?
Hi, I hope I am getting you question right. In case of the perfect split (i.e. 50-50% data in either child node, and all the 0s in one node and 1s in other), the value of 2PLPR i.e. Ψ(large piece) is 1/2, and Ψ(pick cherries) has value of 2. Hence the maximum value that the goodness of split metric can take for the CART algorithm is 1. Is this what you meant?
Thanks for your prompt reply.yes Ψ(pick cherries) has value of 2. Hence the maximum value that the goodness of split metric can take for the CART algorithm is 1.so in this situation what will be the split calculation?
Hi, the calculation for goodness of fit will remain the same. However, in practice, analysts need to ensure that such a variable should not be used as a predictor variable for model building. For such cases remember the old adage ‘If it seems too good to be true, it probably is’.
you have given such a well detailed article on CART. Thanks so much. If I can nit pick on the size of pie I argue that P(L) P(R) is more to make the split even. Taking two combinations P(L)=0.7, P(R)=0.3, and P(L)=0.5, P(R)=0.5 will have higher P(L)P(R) for the second combination as it is even sized split. Excellent article. Thanks!
Hi Bharath, thanks for the kind words. You are absolutely right, the CART algorithm optimizes both the pieces simultaneously through Ψ(large piece), hence the best case scenario is 50-50% data split.
Thanks for your post Roopam.
The way you explain the Cart algorithm in awesome I loved the greedy boy example
Thanks
Another excellent post. Love the cake analogy!
Hi Roopam,
It would very informative and educational to describe classificatio algorithms (Decision Trees techniques (C4.5, CART, Random Forests, Logistic Regression, Support Vector Machine) presenting the essence of the algorithms (without the math whiich sholud be left behind the scene and handled by the software) and where each can be best applied. Then analyze a case and comparing the results. Also use the Ensemble technique to get the best answer.
Thanks.
Hi
I am a fresher to this topic and i am enjoying reading your case studies.I want some clarification in this CART analysis.In the first table we have taken 3 categories like low,medium,high in 1st column(activity in the last quarter ),why do we need to take it as 3 categories , I understand that we need to compare goodness of split to do a decision tree so we can’t take less than 3 and we can take more than three categories ,Am I right ?Please help me in understanding .
We don’t need to take 3 categories for decision trees. It was used to make the case study example easy to understand. Decision trees can easily incorporate multiple continuous variables (like height, income etc.) and multi-category variables (like type of cars, cities etc.). Also, we could use binary variables (just 2 categories i.e. male / female).
Thanku Roopam for clearing my doubt.
wuld be great i fyou could share the data sets
Roopam,
Thank you so much for all the wonderful articles. These are very useful for some one like me who are new the modeling world. I really appreciate you spending lot of time to post these articles. Thanks a lot.
I have few questions on this article. I can see that ” you have divided the total hundred thousand solicited customers into three categories based on their past 3 months activities before the campaign”. How do we choose that category? Is this the result of EDA to understand the variables that have the high correlation to the customer response rate or something else? In other words, how do we choose the variables to use in regression tree?
Another question, why do we have to use CART? we can use even the logistic regression to identify the potential customers who would respond using the 10 deciles breakdown and cut off point and lift and gain chart, right?
I think, article is not telling us the best product to offer to a customer, right? it is to identify the potential respondents and to estimate the potential profits. Is there any model to identify the best product to offer based on their past behaviors?
Hi Poonam:
To answer your first question, these categories where created to simplify the explanation for this article. In practical situations, you will most likely have a numeric value for activity of each customer e.g. 12 visits. You could create classes from these numeric data either based on a business definition or through analytical methods. Multi-node decision trees such as CHAID or C5.0 are some of the analytical methods to create grouped data from numeric data. In this case we started with these classes as raw data so you could assume that a predefined business rule is applied on this data.
To answer your next question, decision trees are often the simplest way to understand relationship between predictor and response variables. They are easy to explain to the business teams. Logistic regression and other machine learning algorithms are not as easy to explain. That’s the reason decision tree, despite their lower predictive power, are still extremely popular within consulting and data science community. Moreover, a bunch of decision trees together in random forest algorithm always perform at par, if not better, with any other machine learning algorithm.
Yes, this a response model to optimize likelihood of purchase. Customer need based models are created by identification of life stage and life style of customers. This requires segmenting customers based on their life style / stage, and identification of right products for each segment.
Hi !! please can you help me by giving me a simple example of process CART about a binary decision tres classification and another example of a binary decision tree regression !!
What happened when there are more than 1 case with the same goodness value (and at their highest value) ?
Which one should we choose?
Hi Roopam,
Well documented article.I was hoping if you could help me understand the derivation of goodness of split formula,as in whats the logic behind the formula. Why are we using 2PLPR and not 4PLPR or something likewise?
Hi Thanks for your article. Could you please explain how the success rate 4.2 % & 5.8 %(shown in fig) is calculated.