This is a continuation of our banking case study for scorecards development. In this part, we will discuss information value (IV) and weight of evidence. These concepts are useful for variable selection while developing credit scorecards. We will also learn how to use weight of evidence (WOE) in logistic regression modeling. The following are the links where you can find the previous three parts (Part 1), (Part 2) & (Part 3).
Experts in Expensive Suits

Mr. Expert – by Roopam
A couple of weeks ago I was watching this show called ‘Brain Games’ on the National Geographic Channel. In one of the segments, they had a comedian dressed up as a television news reporter. He had a whole television camera crew along with him. He was informing the people coming out of a mall in California that Texas has decided to form an independent country, not part of the United States. Additionally, while on camera he was asking for their opinion on the matter. After the initial amusement, people took him seriously and started giving their serious viewpoints. This is the phenomenon psychologists describe as ‘expert fallacy’ or obeying authority, no matter how irrational the authorities seem. Later after learning the truth, the people on this show agreed that they believed this comedian because he was in an expensive suit with a TV crew.
Nate Silver in his book The Signal and The Noise described a similar phenomenon. He analyzed the forecasts made by the panel of experts on the TV program The McLaughlin Group. The forecasts turned out to be true only in 50% cases; you could have forecasted the same by tossing a coin. We do take experts in expensive suits seriously, don’t we? These are not few-off examples. Men in suits or uniforms come in all different forms – from army generals to security personnel in malls. We take them all very seriously.
We have just discovered that rather than accept an expert’s opinion, it would be better to look at the value of the information and make decisions oneself. Let us continue with the theme and try to explore how to assign the value to information using information value and weight of evidence. Then we will create a simple logistic regression model using WOE (weight of evidence). However, before that let us recapture the case study we are working on.
Case Study Continues ..
This is a continuation of our case study on CyndiCat bank. The bank had disbursed 60816 auto loans with around 2.5% of the bad rate in the quarter between April–June 2012. We did some exploratory data analysis (EDA) using tools of data visualization in the first two parts (Part 1) & (Part 2). In the previous article, we have developed a simple logistic regression model with just age as the variable (Part 3). This time, we will continue from where we left in the previous article and use weight of evidence (WOE) for age to develop a new model. Additionally, we will also explore the predictive power of the variable (age) through information value.
Information Value (IV) and Weight of Evidence (WOE)
Information value is a very useful concept for variable selection during model building. The roots of information value, I think, are in information theory proposed by Claude Shannon. The reason for my belief is the similarity information value has with a widely used concept of entropy in information theory. Chi Square value, an extensively used measure in statistics, is a good replacement for IV (information value). However, IV is a popular and widely used measure in the industry. The reason for this is some very convenient rules of thumb for variables selection associated with IV – these are really handy as you will discover later in this article. The formula for information value is shown below.
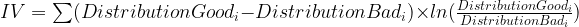
What distribution good/bad mean will soon be clear when we will calculate IV for our case study. This is probably an opportune moment to define Weight of Evidence (WOE), which is the log component in information value.
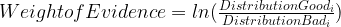
Hence, IV can further be written as the following.

If you examine both information value and weight of evidence carefully then you will notice that both these values will break down when either the distribution good or bad goes to zero. A mathematician will hate it. The assumption, a fair one, is that this will never happen while a scorecard development because of the reasonable sample size. A word of caution, if you are developing non-standardized scorecards with smaller sample size use IV carefully.
Back to the Case Study
In the previous article, we have created coarse classes for the variable age in our case study. Now, let us calculate both information value and weight of evidence for these coarse classes.

Let us examine this table. Here, distribution of loans is the ratio of loans for a coarse class to total loans. For the group 21-30, this is 4821/60801 = 0.079. Similarly, distribution bad (DB) = 206/1522 = .135 and distribution good = 4615/59279 (DG) = 0.078. Additionally, DG-DB = 0.078 – 0.135 = – 0.057. Further, WOE = ln(0.078/0.135) = -0.553.
 Download the attached Excel to understand this calculation : Information Value (IV) and Weight of Evidence (WOE) Download the attached Excel to understand this calculation : Information Value (IV) and Weight of Evidence (WOE) |
Finally, component of IV for this group is (-0.057)*(-0.553) = 0.0318. Similarly, calculate the IV components for all the other coarse classes. Adding these components will produce the IV value of 0.1093 (last column of the table). Now the question is how to interpret this value of IV? The answer is the rule of thumb described below.
| Information Value | Predictive Power |
| < 0.02 | useless for prediction |
| 0.02 to 0.1 | Weak predictor |
| 0.1 to 0.3 | Medium predictor |
| 0.3 to 0.5 | Strong predictor |
| >0.5 | Suspicious or too good to be true |
Typically, variables with medium and strong predictive powers are selected for model development. However, some school of thoughts would advocate just the variables with medium IVs for a broad-based model development. Notice, the information value for age is 0.1093 hence it is barely falling in the medium predictors’ range.
Logistic Regression with Weight of Evidence (WOE)
Finally, let us create a logistic regression model with weight of evidence of the coarse classes as the value for the independent variable age. The following are the results generated through a statistical software.
| Logistic Regression Results (Age Groups and Bad Rates) | |||||
| Predictor |
Coefficient |
Std. Er |
Z |
P |
Odds Ratio |
| Constant | -3.66223 |
0.0263162 |
-139.16 |
0 |
|
| WOEAge |
-1 |
0.0796900 |
-12.55 |
0 |
0.37 |
If we estimate the value of bad rate for the age group 21-30 using the above information.

This is precisely the value we have obtained the last time (See the previous part) and is consistent with the bad rate for the group.
Sign-off note
I wish there was an instrument similar to information value available with us to estimate the value of information coming from so called experts. However, next time when an expert on a business channel gives you the advice to buy a certain stock, take that advice with a pinch of salt.
Read the remaining part of credit scoring series
- Part 1: Data visualization for scoring
- Part 2: Creating ratio variables for better scoring
- Part 3: Logistic regression
- Part 5: Reject inference
- Part 6: Population stability index for scorecard monitoring
References 1. Credit Risk Scorecards: Developing and Implementing Intelligent Credit Scoring – Naeem Siddiqi 2. Credit Scoring for Risk Managers: The Handbook for Lenders – Elizabeth Mays and Niall Lynas
very nice explanation, terrific. not much literature is available over the web on IV and WOE. Also the examples selected help to understand the concepts easily
How would you perform logistic regression with WOE in MS Excel and what would you use as you dependent variable?
In my opinion, Excel is not the best platform to perform logistic regression. However, there are Excel plugins that you could use for the purpose, such as XLMiner etc. You could be a little adventurous and use inbuilt Excel-Solver to optimize logistic regression equation – though this will be a little too ambitious for a beginner. Learning logistic regression on Excel also won’t help you much for most applied large data projects because of the constraint of number of rows in Excel. I would recommend you use R or SAS or SPSS.
Excellent explanation.
Could you please elaborate on the below also –
1) How does WOE ensure Linear Transformation with example ?
2) How does that particular formula for IV decide whether a variable is important or not? (Basically why that formula? why log in that ?)
Thank you for your response.
I have tried to use R using the Riv Package but as am not sure what the independent variable will be for grouped data, I haven’t managed to make this work. i do not have access to SAS or SPSS as they are unaffordable otherwise would have managed. Do you have any articles that you have written or guidelines on the actual regression for grouped data in R?
Thanks
Nhlanhla
SAS Enterprise Miner offers interactive-grouping and interactive-binning of independent variables to create weight-of-evidence. However, for R I am not sure if there is a similar package. In this case you will have to create groups or bins through the traditional way of eyeballing the normalized histogram (check out a previous article link). You could also use one variable decision trees to get clues about actual size of the bins. SAS eminer also uses the same logic at the back-end. It’s a little time consuming in R but you will learn more by doing it the hard way.
HI Roopam – Suppose we made same logistic model with two numeric variables , AGE and CREDIT_SCORE and I have no missing values for both the variables.Then, Woudn’t the IV and WoE for AGE and CREDIT_SCORE remain same ?
HI Roopam
Would you please inform how to calculate studentized S(C) value of W+ and W-
or studentized S(C) from Dg and DB in your explanation here
some explanations say it is the standard deviation of C or (DG-DB)
Thanks so much
Hi, aptly explained.. though an article ‘use of WOE for binning’ will be a good extension of this article…if its thr already please share the link…thanks!
Hi – Thank you very much for putting these things together, your blog is very helpful. I have a question about using WOI in building logistic regression model. While fitting the model it seems OK to use WOI as predictor as we have values of dependent variable (good, bad). But how we will score the model when we do not have any information about dependent variable how are we going to calculate WOI? Are we going to use same WOI in scoring that is calculated while fitting the model?
Hi Sanjay, Once you have created your logit model using WOE, the same WOEs are used for prediction as well.
Hi,
Very useful blog indeed. How to use WOE for binning…please explain with example
Thanks,
Hi, WOE is not used for binning; WOE is a numeric representation of bins (i.e. log of odds of each bin). Binning is carried out either through visual analysis of data as described in the previous part of this case study by creation of fine & coarse classes, or by using automated algorithms (like the binning algorithm in SAS E-miner).
Hi Roopam – Thanks for the website. It’s very informative. I am new to this…can you explain what’s the value in incorporating WOE into a logistic regression model, vs. just leaving it as is like in your Case Study Part 3? Especially if both methods provide the same P(bad loan)?
Thanks!!
Through WOE you convert discrete groups to a continuous variable. There are many benefits to this. For instance, you could identify and remove multicollinearity much more easily with continuous variables.
Got it! Thank you!!
Roopam…We have a paradoxical cenario inside your answer. You written: “WOE convert discrete groups to a continuous variable…” … but we have a continuous variable already (Age)… Further more the original variable have more cardinality… and more cardinality means (in probability basis) less odds to happen multicollinearity. So… just convert to continuous perhaps is not the best answer. I don’t have the right answer too. Perhaps someone reading this may help us. Anybody may do it?
You should use a continuous transformation of the age variable – use it raw or find a transformation, e.g. logarithm, until the relationship is linear with the log odds of the event. This allows the use of the age variable without loss of information from discretisation, that occurs due to categorisation (binning/bucketing/grouping) of the variable.
I know it could be a bit confusing that we transformed a continuous variable (age) to discrete bins and then further transformed the discrete bins to WoE i.e. a continuous variable. This, however, will help our modeling process big time. Firstly, it will take care of the non-linear relationship between the original continuous variable and the dependent variable (bad rate). Notably, logistic regression doesn’t work well for non-linear relationships between independent and dependent variables. Secondly, it will produce a scorecard format which is preferred by business users since it is easy to interpret and implement. And finally, by using WoE you reduced the dimensionality of the model since several dummy variables (one-hot encoded variables) are now reduced to much fewer continuous variables. The dummy variables, as you would appreciate, produce a patchy model because it is possible that not all bins of a variable turn out to be significant
Hello Roopam ,
Is WOE and IV methods works on small data sets? Suppose I have a data set of 1800 rows and I have to predict the customer behavior. So will it work properly or not? Or what other options we have if we want to predict customer behavior whether they are good or bad?
Hi Roopam,
How do I calculate points for a categorical variable in a scorecard. That is how to combine WOE of the attributes and coefficients from logistic regression and what to do about reference category of the categorical variable? Any pointers in this direction wouldbbe helpful.
Thanks
Srikanth
For calculating score points one transforms logistic equation, with WOE, to score point scales. It is a fairly straight forward process. I think, all the books referenced in the linked article will have a dedicated section on scoring.
Hi Roopam,
Is it required that WOE vary monotonically with respect to attributes for a continuous variable?
Thanks
Srikanth
And how do we deal with attributes with zero bad cases.
As mentioned in the article, this is an unlikely case for a large dataset. Both, information value and weight of evidence cannot tolerate attributes with zero bad cases. You will have to modify your attributes in such an event.
Hi Srikanth,
I am not sure about your definition of ‘vary monotonically’. If you mean that they are desired to have a specific trend the answer is yes. This makes sense since you don’t want some random variation (zigzag movement of WOE) to be part of your scoring model. Hope this helped.
So let’s say WOE has a V shape with respect to the attributes of a continuous variable. Is it legal to still use this WOE as an input to the logistic regression? Thanks
Srikanth
What do you do if 1 or more of the decile groups of the variable under study have zero percentage good or bad?
Should I reduce the groups from being a decile to lesser or make the IV of the decile group = 0?
There is no condition that you need to use only deciles for information value, and weight of evidence, anyway while coarse classing you reduce the number of bins. So I recommend you join groups with zero bad/good records to adjacent groups and reduce the number of groups. Assigning the IV of the decile group = 0 is completely wrong since this group has infinite or in other words really large IV.
Hi Roopam,
1) Can WOE have a V shape with respect to the attributes of a continuous variable and it makes business sense. 2) Is it legal to still use this WOE as an input to the logistic regression?
3) When I include WOE variables in logistic reg model, I see that some of the WOE variables have positive coefficient, which is unexpected because going by the definition of WOE, it is reasonable to assume a negative coefficient for a WOE variable. Is this usual?
Thanks
Srikanth
Hi Roopam, please help me with the above questions. Thanks,
Hi Shrikanth,
Sorry for delay in response, was tied up with many things. To answer your first two questions:
Yes WOE can have V or U or inverted U shape. This is a non linear relationship which needs to be handled similar to any other non linear relationship for logistic regression. For instance, age with bad rate could have U shape curve and this is logical.
For your third question you will have to elborate the way you are using WOE, variables, model, software package, and logit coefficients for me to explain the results.
Best,
Roopam
I’m using WOE variables (not raw variables) as IVs in logistic reg. Since WOE is another way of expressing log odds, I assume linearity of logit is taken care of. As WOE variables are being added to the model, there are changes in signs from negative to positive for some WOE variables. Don’t know how to interpret this.
I’m using SAS – proc logistic.
Check for multicollinearity in your variables, that’s the most likely cause for what you are observing.
Check multicollinearity in WOE variables (which are input to my logistic reg) or raw variables?
I checked VIFs of WOE variables and found them to be acceptable (<2).
hi. in your example there are 4 groups and thus 4 woes. are you inputting all of them in your logistic equation ?
The new variable with WOE is a continuous variable hence you are no longer using descrete groups. This is like developing regression models with any other continuous variable.
Hi Roopam,
I’ve got some output in SAS with my intercept and beta stiamtes for a variety of WOE transformed categroical variables.
I cannot determine the resulting attribute points allocation, is there a formulae?
Ultimately i want a score distribution that is defined by PDO -20 points 160 doubles the odds.
Hi Roopam,
Just wanted to know is there any range of IV? What can be the maximum and minimum value (0?) of IV?
I have found that IV and WOE works well with small number of covariates and it fails badly with increase in variables. Computation of these stats are very expensive. I tried IV in retail domain to do variable selelction for category models (4000 variables and 500k obs). It took 10 hours just for one model and I had to build around 200 models!!!
Excellent article, thanks. Would an IV for a single variable of 1.8 be suspicious?
This variable in question is a bureau score.
Yes, IV of 1.8 is highly suspicious. Since credit bureau is a 3rd party aggregator’s data – it is possible that information about your own bad rate is embedded in this data.
Let’s assume that everything is fine with this data, even then extremely high IV for a variable will make your model highly unstable. Since the entire predictive power is captured in just one variable. Usually you want to avoid such variables in your model.
Hi,
Can you please explain how to find woe of dummy variables(0,1) and use it in logistic regression and what to do if monotonicity of groups is not there.
The process to derive information value (IV) and weight of evidence (WoE) for a binary variable will stay the same as described in this article for multi-nominal groups. About your second question on ‘monotonicity of groups’, the important idea here is to find logical trend between dependent and independent variable.
Hi Roopam,
Very good material! easy to understand and useful techniques! Thank you. I am wondering is it possible to publish the data you used for the case study. So readers can learn your stuff by practice. That will be very helpful. Thanks.
Jason
Hi, How would you interpret the odds ratio of 0.37 here. Thanks.
After converting variable (i.e. var1) into WOE, and using WOE as a predictive variable. How should i interpret the log odds output of var1 from the regression? Will i need to multiply var1 WOE against var1 Log odds of the predictive variable?
Excellent explanation, thank you very much but
the table says that if IV is bigger than 0.5, it’s misleading.Can you explain why it’s so?
If there’s a satisfying answer, can changing the ranges be a solution.
High IV corresponds to higher predictive power for just one variable – there are two reasons why you want to be cautious about a high IV for a variable i.e.
1) The high predictive power for the variable could point to ‘too good to be to true’ kind of scenario – one needs to be careful about such relationships and explore the logical reasons behind the high predictive power. Also check whether this relationship will hold true in the future as well.
2) Secondly, even if the the trend is logical, the final model will have a very high dependence on just one variable. It is always better to create a broad based models where many variables share the load of prediction to achieve higher accuracy in the future.
Thanks, very informative!
Dear Roopam,
I have the same issue as with part 3. I manage to get the same nuber for the coefficients however the z-statistics are nowhere near. Note that I have verified this with various statistical softwares such as MATLAB, EXCEL ( I have a logit VBA function in EXCEL) and R. So I am pretty sure it is not a software issue rather an input issue.
Because the devil lies in the details could you please tell me exactly (or even post as a separate EXCEL file) how my dependent and independent variables look like? i.e. how many observations they have etc.
If I understood correctly the dependent variables (Y) is bad rates and the dependent (X) now is WOE for age. So both Y and X have 4 observations. If that is the case how are the standard errors so small with so few observations?
I hope this email is clear. If I have confused you please let me know and I will try and make my question more precise.
Thank you
Panagiotis Ballis-Papanastasiou
Dear Panagiotis Ballis-Papanastasiou,
I downloaded and checked the excel file and I am sure you are mistaken with something very important. The contennts of the excel file are not the raw data but summary (like histogram counts for the 4 bins w.r.t. age), the ctual number of observations is 60801 (see the total number of loans). So what you do is to transform the feature age first into a discrete variable (by age grouping) and then each category value into a continuous value using WOE.
Hellow
please i need to knew credit scoring algorithm from A to Z , i need it how can start how its calculation by hand
Thank you
What if we want to bring a trend in woe values,like either values go in increasing manner or in decreasing manner?
Not sure if I understood your question, please rephrase.
Hi Roopam,
Thank you for the informative blog.
I’ve gone through almost all the articles and understood more about modeling.
One question about WOE. How do you interpret a WOE? how to interpret the upward trend in the Excel file?
Does a higher WOE means higher risk?
Cong
Is WoE still suitable for data with a low number of occurences of the target ?
No
So oversampling or undersampling would not work either?
What is your sample size for the events and non-events? It is advisable to have 1000 observations of each. When you have strong prior business knowledge, even then at least 150/200 observations of each type is required. Over/undersampling are to balance the sample and are not good for this purpose.
I mean percentage wise small. The number of events is about 20.000 and the number of non-events is about 20 million…
Yes, that’s fine. This is a typical rare event problem.
Mr Upadhyay,
I read your comments on WOE transformation and the linearity, WOE in always inversely to the log odds..couldn’t find this in your answers. A WOE transformation will never will a V shape trend, because bad rate and WOE are inversely proportional!
Hi, in the previous article you use logistic regression with dummies. Is it better to use logistic regression with dummies or WoE?
Using WoE is better in my opinion because working with continuous variables is much straightforward than several discrete dummy variables for regression.
Can IV be larger than 1
Create a perfect fit in the Excel to calculate for yourself the upper bound of IV.
what do you mean by perfect fit?
Do you mean there is just 1 category that includes all goods and bads in entire dataset?
I have created a toy example with 2 categories, the first category includes all goods and the second includes all bads. So when I compute WoE1 I get log(1/0), 0 in denominator because bads_1 = 0. When I compute WoE2 I get 0 in log numerator log(0/1). Is that the perfect fit?
Yes, that’s the max value. Now, add a little impurity to your perfect fit to notice how the upper bound of IV changes.
Got it, IV max value is plus infinity, thank you!)
You are welcome!
Hello, in the process of credit scoring, WOE value and IV this is used to get the score for each group, maybe you know where the number below is:
Define a target:
Target Score Value (ts): 600
Inverted Target Odds (to): 50
Read as: at my target score 600 the ods should be 1:50
Define slope:
points to double the odds (pdo): 20
thank you
Hi Roopam, thanks for sharing this tutorial.
I would like to ask how do you get just one coefficient: WOEAge = -1 as output after you fit the logistic regression model. Since the classes for the variable age are 4, you will have 4 different weight of evidence input values as independent variables ( one for each class) and therefore I would expect to have 4-1= 3 weight of evidence coefficients at the output (since one of them will be the “reference” point). Instead, you end up with just one coefficient for WOEAge.
Could you explain this as well as what was exactly the fitted model that you used at the logistic regression?
Thank you
Hi Roopam! Thanks for a learner friendly content. 🙂 I come from a non-stats background. I am using IV for my PhD thesis. While writing about it I explained it as “One limitation of IV is that it does not have a standard range (like correlation which ranges between -1 to +1). Hence, heuristics and general guidelines are often used to select features by benchmarking IV values against the maximum IV observed in a particular dataset. In line with such established guidelines (Ref), all predictors which had information value of >=25% of the maximum IV were categorised as “Strong”, between 10-25% were categorised as “Moderate” and less than 10% as “Weak”; I am unable to find reference to cite this. As you know it is mandatory in academic writing to validate it by references. Can you please help me with this? In other words, help me with some publications to refer this section.
Hi Roopam,
Though I hold experience in credit underwriting, I am a newbie with credit scoring. Your article is of a lot of help for beginners like me. I have some doubts with this part:
1. How does using WOE of the course classes of age variable improve the model??
2. Somewhere else I learnt to use WOE and IV for course classing independent variables.. Is this a correct approach?
3. Can we use IV for reducing the number of independent variables and how does it fair against other options such as PCA, Forward selection, Backward elimination etc. available.