
Does Bayes’ Theorem Have a Better Answer? – by Roopam
Data Analytics Challenge 1 – The Shady Gambler
 This is the final part of the first data analytics challenge on YOU CANalytics. You could find the previous parts at these links: Part-1 & Part-2. As mentioned earlier, these challenges require your participation for the investigation to move ahead. You had some really good discussions in the previous parts: Discussion Part 1 & Discussion Part 2. Now, let me move the story further based on your investigation. Again, this post will require your participation for closing the case.
This is the final part of the first data analytics challenge on YOU CANalytics. You could find the previous parts at these links: Part-1 & Part-2. As mentioned earlier, these challenges require your participation for the investigation to move ahead. You had some really good discussions in the previous parts: Discussion Part 1 & Discussion Part 2. Now, let me move the story further based on your investigation. Again, this post will require your participation for closing the case.
In the previous parts, you were approached by Scotland Yard to investigate charges against a gambler with dubious character. You are investigating the possibility of the gambler being a cheat or his die being biased. You analysed his past 1000 throws of a die and found the probability of throws being random (non-biased) = 0.164 or 16.4% (Credit : Rishabh). As many of you pointed out, this doesn’t conclusively make the gambler into a cheat.
Does Bayes’ Theorem have a Better Answer?
However, there is key information that has been available to you throughout the case: the gambler has a dubious character. This means he has been investigated before for the charges of being a cheat. You asked Scotland Yard about the chances of the gambler being a cheat from their previous investigations. They gave you the prior probability of 0.9 or 90%. This 90% is a mix of their investigation, and professional judgement. Interesting, professional judgement and feelings are converted into a probability figure here. You used this information and scribbled down a few calculations in your detective notebook. This is the same page from your notebook. Please click on the image to enlarge it.

Bayes’ Theorem Calculation
You have used Bayes’ Theorem in this calculation. Read the previous articles to get an intuitive understanding of Bayes’ Theorem and Bayesian Inference.
Let us see what you scribbled in your notebook. Towards the extreme left you wrote the prior probability i.e.
P(Gambler is a cheat) = P(Cheat) = 90% or 0.9
This made chances of him not being a cheat equal to
P(Gambler is not a cheat) = 1 - P(Cheat) = P(~Cheat) = 10% or 0.1
Then you wrote down the probability of the event (the gambler’s 1000 throws) if he is not a cheat P(~Cheat). This probability is 0.164 or 16.4 %. I hope you noticed this is the probability calculated through Chi-square test by you in the previous part.
P(Observed Throws|~Cheat) = 16.4% or 0.164
Similarly, you found the probability of the event (Observed Throws) if the gambler is a cheat P(Cheat)
P(Observed Throws|Cheat) = 1-0.164 = 83.6% or 0.836
Now, came the crucial part of the calculation of posterior probability using Bayes’ Theorem (extreme right calculation in your scribbling). This is the probability of the gambler being a cheat in the light of the new evidence / event (Observed Throws).
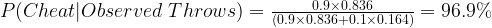
This made the gambler ~97% likely of being a cheat. You shared your results with Scotland Yard and they immediately started working on the paperwork for the warrant against the gambler. You came back home after that. You knew Dr. Watson who was silently watching you all this while with a look of complete amusement is struggling to keep his curiosity and questions to himself. You requested him to wait for a few more minutes and prepare some tea for both of you. Now, you have both settled into comfortable seats in your drawing room with your cups of tea. Dr. Watson is almost turning red with excitement to learn answers to his questions. You are equally excited to settle his curiosity, and hear his praises for you. He has immediately overloaded you with these questions:
| 1 | What was the relevance of earlier evidence (prior probabilities) against the gambler to solve this case? |
| 2 | What if there were no prior probabilities, would you start with 50-50 chances of the gambler being a cheat? How will this change the calculation? |
| 3 | What is your opinion about converting experts judgement into prior probabilities? |
| 4 | Why do you think Bayes’ Theorem has a better solution to this investigation than simple Chi-Square Test? |
| 5 | Now that you are more relaxed, do you still think your calculation for Bayes’ Theorem was correct? |
| 6 | Does Bayes’ Theorem offer a better mechanism of building a case with incremental clues? Is this similar to detective or scientific investigation? |
Again, you don’t need to answer all these questions just take your pick and start a discussion in the “leave a comment” section at the bottom. Please mention the question number(s) at the beginning of your discussion for other readers to follow your train of thought. I look forward to your answers with the same eagerness as Dr. Watson!
We have relation P(A/B)*P(B)=P(B/A)*P(A).
Dividing both sides by P(B) we obtain
P(A/B)=P(B/A)*P(A)/P(B)
The picture on top shows the incorrect notation of Bayes’ theorem.
Jan: good to hear from you after a while. Thanks for suggesting this correction – have fixed it. It was a good discussion we had the last time around on Bayes’ Theorem and statistics. Look forward to hear your ideas on this challenge.
Answers to questions:
1. Relevance of collateral information /data to be decided by the investigators. Bayes theorem only provides a way of incorporating new or collateral information in the decision making.
2. If no information about prior is available, try conducting a survey! Or may be use data from the historical records of other cheats. 50% chance prior isn’t going to change anything in the posterior probability (same as observed chance of 16%).
3.No opinion. Just that it should come from experts or from people who have some definite perspective from past experience or superior knowledge.
4.Bayes is only a way of synthesising the ‘new’ information into what we already have. Superiority will depend on:
A. The degree of variability /uncertainty around the experts opinion(prior data)
B. The degree of variability in the observation (likelihood)
C. Size of the direct data( how much data/events have gone into the calculation of 16% odds which we have.
You can search through ‘Bayes credibility estimates’ to find out the relationship between point A,B and C, and the overall assertion about the superiority of Bayes estimates over a frequentist model of odds.
Rest of the answers in my next comments.