
Building Blocks of Machine Learning – by Roopam
In this 3-part series of articles, you will gain an intuitive understanding of some fundamental concepts in machine learning such as:
-
- Building blocks of curves
- Non-linear regression
- Curve fitting and overfitting
- Regularization to prevent overfitting
- Hyper-parameters in machine learning
- Cross-validation to fine-tune models
You will also get hands-on practice to understand these concepts better. For this post, we will primarily focus on the building blocks of curves, non-linear regression, and curve fitting. This introductory article will serve us well when we explore the fundamental concepts of machine learning, i.e. regularization, hyper-parameter tuning, and cross-validation, in the next parts.
Before we start, let’s appreciate the beauty of curves through this Batman curve formed with different mathematical equations. R code for Batman curve.

This Batman Curve is a reminder that mathematical equations are capable of forming every possible shape. This flexibility of equations also makes them susceptible to overfitting as we will learn in the next segment.
Curve Fitting and Overfitting

Andrew Ng, in his brilliant lecture series on machine learning and AI, described supervised machine learning as a multidimensional curve fitting. The idea is to identify the best curve or function of the x-variables (aka predictors) to estimate the y-variable (aka response) with minimum error. Notably, supervised learning dominates most machine learning applications for business.
Curve fitting, essentially, is similar to the game of connecting the dots where you try to complete a picture. In case of data, dots are the data points and idea is to produce the best fit for the observed data which is generalizable for the unobserved data. Non-linear curves are highly flexible and can fit any observed data to perfection. To understand this have a look at this Calvin and Hobbes comic strip.

Essentially, with non-linear curve fitting, you are providing the algorithm the same level of creativity Calvin has opted to exercise at the end of the comic strip. This level of creativity is capable of producing a masterpiece but is equally capable of creating a grand mess. Before we learn how to make masterpieces through non-linear equations, let’s understand the reason why non-linear equations fit and over-fit so well. The root of this is in the Taylor series which you might remember from high-school.
Building Block of Curves – Taylor Series
 One of the primary goals for all fields of science is to identify the building blocks of nature. For instance, physicists identified atoms as the building blocks of matter. You, me, and everything we see around, dead or alive, are formed out of atoms. Atoms are further divided into electrons, protons, and neutrons. The combination of these elementary particles is responsible for everything in the known universe. Things that are extremely fundamental and simple can produce the complexity of the order of the universe.
One of the primary goals for all fields of science is to identify the building blocks of nature. For instance, physicists identified atoms as the building blocks of matter. You, me, and everything we see around, dead or alive, are formed out of atoms. Atoms are further divided into electrons, protons, and neutrons. The combination of these elementary particles is responsible for everything in the known universe. Things that are extremely fundamental and simple can produce the complexity of the order of the universe.
Like the elementary particles that formed the entire universe, could there be elementary units of all mathematical functions and curves? You must appreciate that functions could have infinite forms such as the sine function, the exponential function, the Batman function etc. Moreover, a combination of functions is capable of creating complexity of the magnitude of the universe. So, is there a fundamental unit of functions? The answer is yes. The Taylor Series states that any complicated function  , including the Batman curve, could be described as a linear combination of x and its infinite powers i.e x2, x3…, x∞. At this point, let me throw in a daunting looking equation but trust me it will become quite simple when you will continue reading this article. The special form of the Taylor series at x=0, aka Maclaurin Series, is represented as:
, including the Batman curve, could be described as a linear combination of x and its infinite powers i.e x2, x3…, x∞. At this point, let me throw in a daunting looking equation but trust me it will become quite simple when you will continue reading this article. The special form of the Taylor series at x=0, aka Maclaurin Series, is represented as:
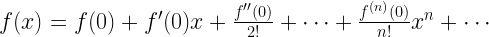
Here, 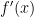 is the first differential of the function and
is the first differential of the function and  is the nth differential. Essentially, we can mimic a complicated function , like the Batman curve, with just x and its polynomials. If we do the Taylor Series calculation long enough i.e. higher powers of x (yeah, like we have nothing better to do) then we can find the exact value of the function at any point. To make things easy to understand let’s have a competition between…
is the nth differential. Essentially, we can mimic a complicated function , like the Batman curve, with just x and its polynomials. If we do the Taylor Series calculation long enough i.e. higher powers of x (yeah, like we have nothing better to do) then we can find the exact value of the function at any point. To make things easy to understand let’s have a competition between…
Non-Linear Regression Vs. Taylor Series
Everyone loves a good competition and today in the ring are non-linear regression and Taylor series. They will compete against each other to approximate the sine function between -3π to 3π which looks like. You could use this R-code to reproduce the results you will see in the subsequent sections: Non-linear regression Vs. Taylor series.

This competition will help us to understand the intuition behind non-linear regression which often has polynomial forms of the predictor variables (X). It will help us understand how these two different methods of approximation have different objectives and how these objectives rule the way these methods approximate response variable (Y). The objectives for 2 methods can be described as:
Objective non-linear regression: to minimize the overall error for the entire sample. This equation describes the generalized polynomial (non-linear) form of the regression model.
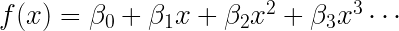
Here, the idea is to identify beta (β) parameters with the help of observed data (x and its polynomial forms).
Objective Taylor Series (at x=0): to find the best approximation for y using x around x=0
Taylor Series for sine function at x=0 is described as:
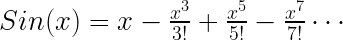
This series expands to infinite powers of x and it can be written in the general form as:
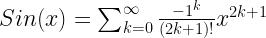
When we use a high degree of polynomials of x, the beta coefficients of regression and Taylor series coefficients will look identical. Keep this in mind when you see curves for non-linear regression and Taylor series converge. So, let the competition begin…
Non-Linear Regression and Taylor Series – Race to the Finish
Remember, we are trying to fit both Taylor series and non-linear regression on data generated by the sine function. To begin with, let’s just use the first power of x for both the methods. With just x as the parameter, this is a linear regression. Remember, Taylor series is approximating the curve near x=0 and regression is using the entire dataset between -3π to 3π.
 With just x, these are not very good approximations. The regression line in blue has the following equation (you can get this easily with the R code provided at the top)
With just x, these are not very good approximations. The regression line in blue has the following equation (you can get this easily with the R code provided at the top)

Taylor series, on the other hand, has this form with just x.
These two equations are nothing like each other. But you will notice that they will become identical when we will increase the polynomial powers of x in the calculation.
5th-degree Polynomials of x
Let’s turn up the heat a bit in this competition. We will give both Taylor series and regression all the polynomials of x till the power of 5. This is the equation we are fitting with both the methods.

The Taylor series, in this case, will be:
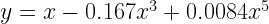
The regression equation is:
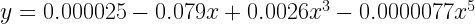
See how regression has started to agree with Taylor series here. It has set the β values for even powers of x, i.e x2 and x4, as zero. The magnitude for coefficients are still different but that will also converge when we will add higher polynomials of x to the equations. This is how the fit looks like for 5th-degree polynomials.

15th-degree Polynomials of x
Ok enough with this club level competition, let’s take both these methods to the Olympics. We will provide them with 15th-degree polynomials of x.
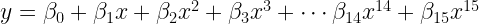
The regression equation has fit the data almost perfectly. Taylor series is still trying to catch up. Remember, they had different objectives.

The winner, in this competition, is the non-linear regression.
25th-degree Polynomials of x
Remember, the Olympics are about participating not winning. So, let’s give Taylor series enough time to finish the race. With the 25th-degree polynomial term, the curves look identical.
 The moral of the story is if you give enough polynomial terms of x to the equation it will be able to fit any curve perfectly. But is perfection good? The answer is almost always no when it comes to data analysis. Perfection reflects overfitting for most models especially if they are not tested against unobserved data.
The moral of the story is if you give enough polynomial terms of x to the equation it will be able to fit any curve perfectly. But is perfection good? The answer is almost always no when it comes to data analysis. Perfection reflects overfitting for most models especially if they are not tested against unobserved data.
For instance, if you built the sine curve model with even higher degree polynomials, say 35th-degree, you will see that the R code will return this interesting warning statement:
>Warning Messages:>1: attempting model selection on an essentially perfect fit is nonsense
This means the regression fit is perfect i.e. with zero error. R is highlighting the essential fact in data analysis i.e. perfect fit is nonsense.
Sign-off Note
In data analysis, like every other endeavor in life, perfection is a mirage. Perfection signifies overfitting and in the next articles, we will learn how to avoid the trap of overfitting and sketch masterpieces using non-linear regression. Gear up to learn some essential concepts in machine learning i.e. regularization, hyperparameter tuning, and cross-validation. Hope to see you soon!
Thanks for sharing..
Can any polynomial equation used for describing the boundaries of a country.. I mean can any equation when plotted in graph give a perfect picture of any country in the globe?
Interesting that you asked a similar question to the ones Benoît Mandelbrot asked in the 1960s. These kinds of questions turned out to be the inspiration for an exciting field in physics and mathematics called Fractal Geometry. The field is about how simple polynomial equations can form such intricate patterns in nature – including leaves, clouds and the coast of England. Do check out these links and original papers by Mandelbrot:
https://en.wikipedia.org/wiki/How_Long_Is_the_Coast_of_Britain%3F_Statistical_Self-Similarity_and_Fractional_Dimension
https://en.wikipedia.org/wiki/Coastline_paradox