
Machine Learning: Regularization (Ridge, Lasso, and Elastic Nets) – by Roopam
In the previous article, we started with the theme that overfitting is an inherent problem in machine learning associated with big data. Essentially, if you have many variables and their polynomial terms (X-variables) in a model you could fit any response data (y-variable) to perfection. This perfect fit for the observed data is overfitting since this model will generalize poorly to the unobserved data. In this post, you will learn the ways of overcoming this problem with regularization techniques. But before that let’s visit a funfair!
Regularization and Funfair
 I was 6 or 7 when one evening my grandmother took all her grandchildren to the local funfair. At the entry, she announced that we could take as many rides as we liked and as many times as we wanted. Yay! shouted all us kids with joy. She continued – as long as the expense was kept under 2 rupees, and we would get back home by 7 PM. This second instruction could have been a big dampener. However, I remember having a great time at the fair managing grandma’s instructions.
I was 6 or 7 when one evening my grandmother took all her grandchildren to the local funfair. At the entry, she announced that we could take as many rides as we liked and as many times as we wanted. Yay! shouted all us kids with joy. She continued – as long as the expense was kept under 2 rupees, and we would get back home by 7 PM. This second instruction could have been a big dampener. However, I remember having a great time at the fair managing grandma’s instructions.
Many years later, when I was in Orlando, I visited Disney Land (or was it Universal Studios?) with my friends. This was a much grander funfair than the one my grandma took me to. I managed to get a 3-day pass at a discounted price. This time I could actually take as many rides and as many times I wanted. I was finally liberated from my grandma’s instructions. After I took a few head-spinning rides, I was so rattled that by evening I opted to rest under a tree while my friends were finishing up. I didn’t go to the amusement park for the remaining two days. I guess constraints imposed by my grandma were not all that bad.
You will soon realize that my grandma’s instructions and regularization in machine learning are quite similar.
Regularization – Intuition (Grandma to the Rescue)
In the subsequent segments, you will notice a few intimidating equations. However, you must not get intimidated by them since they are very similar to my grandma’s instructions. The first instruction was to try as many rides as you wish. This instruction had no constraints. In terms of the objective for machine learning it can be represented as:
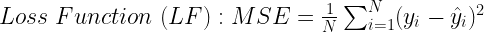
Now, you must have seen this equation for the loss function in one of my earlier posts on gradient descent optimization for linear regression. This loss function is essentially the mean square error (MSE) in the estimation of the y variable using the x variables. The objective is to minimize the MSE or the loss function. The y-variable is estimated by the linear combination of the X variables.
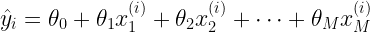
Here, the equation can take any value for the θ parameters between -∞ to ∞. This complete freedom also leads to overfitting since there are no constraints on the θs. Now, similar to grandma’s second instruction, let’s add a few regulations on this complete freedom. The most commonly used regularizations are L1 and L2. Let’s start with L2 first.
L2 Regularization: Ridge Regression
Here, I will take a few liberties to create linkages between my grandma’s second instruction and regularization. Let me relive her instructions one more time. First, let’s just consider the time constraint imposed by her i.e. to get back home by 7 PM (spend an hour at the fair). Let’s assume there were 10 rides and each ride takes 3 minutes. Then I could have taken all the 10 rides in the first 30 minutes. The remaining 30 minutes could then be spent on rides on which I had the most fun.
This is similar to L2 regularization which is ridge regression in this case. This regularization term is added after MSE in the loss function i.e. λ∑θ2. This is similar to saying spend 1 hour in the fair not infinite. Here λ is a constant which is also caller hyper-parameter.
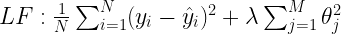
This constraint is imposed on the θ parameters. Essentially, all the θs will have some small value similar to how I spent the first 30 minutes exploring all the rides. Then the θ parameters with the highest contribution to minimizing MSE will get higher values. Hence, L2 regularization assigns values to all the θ parameters or all the X variables feature in the final equation.
L1 Regularization: Lasso
The other constraint by my grandma was on the total expenditure. As a kid, growing by in India 35 years ago, time was always more available than money. Hence, I could not have taken all the rides. Here, I would observe and evaluate the rides from a distance first. Then I would take the rides I believed I would enjoy. This is L1 regularization or Lasso. The additional term for this is again at the end.i.e. λ∑|θ|

Lasso or L1 regularization will ensure that only useful predictor variables or Xs get a weight or non-zero θ parameters. Lasso essentially sets θs to zero for less useful x variables.
Elastic Net Regularization: Ridge + Lasso
Elastic net is essentially imposing both L1 and L2 at the same time. This is similar to my grandmother’s instruction about managing both time and expense at the same time. Notice, both these terms are at the end of the loss function.
![LF: \frac{1}{N} \sum_{i=1}^{N} (y_{i}-\hat{y}_{i})^{2}+ \lambda\left [ (1-\alpha)\sum_{j=1}^{M}\theta_{j}^{2}+ \alpha\sum_{j=1}^{M}\left | \theta_{j} \right |\right ]](https://s0.wp.com/latex.php?latex=LF%3A+%5Cfrac%7B1%7D%7BN%7D+%5Csum_%7Bi%3D1%7D%5E%7BN%7D+%28y_%7Bi%7D-%5Chat%7By%7D_%7Bi%7D%29%5E%7B2%7D%2B+%5Clambda%5Cleft+%5B+%281-%5Calpha%29%5Csum_%7Bj%3D1%7D%5E%7BM%7D%5Ctheta_%7Bj%7D%5E%7B2%7D%2B+%5Calpha%5Csum_%7Bj%3D1%7D%5E%7BM%7D%5Cleft+%7C+%5Ctheta_%7Bj%7D+%5Cright+%7C%5Cright+%5D&bg=ffffff&fg=000&s=2&c=20201002)
This time we have two hyperparameters. The first hyperparameter is lambda (λ) similar to the previous equations. The second hyperparameter is alpha (α) which takes the value between 0 and 1. When α is 1, then the regularization term is purely lasso. For α=0.5, the regularization has 50% regularization from lasso and 50% form Ridge. Now, let’s solve the problem of the sine function we started in the previous part.
Sine Curve – Regularization to Reduce Overfitting
We had the population for the sine curve displayed with the gray line in the plot between -3π to 3π. This is an unusual situation where we know the population distribution with complete certainty – unlike any other analysis in real life. The R-code to replicate the analysis is Regularization – Lasso & Ridge (Elastic Net) and Cross-Validation
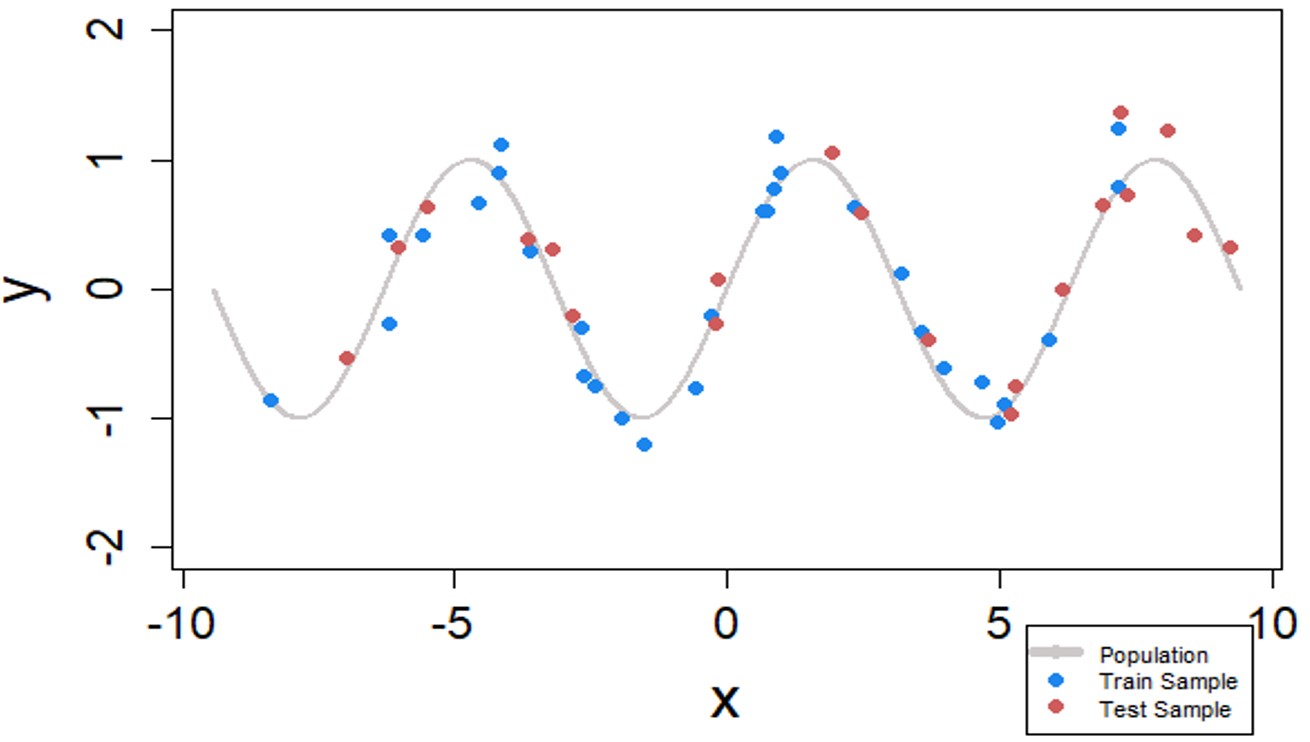
Now, we will draw the training and testing sample from the population. Notice, the sample data (dots) are not exactly on the population line. Since the act of measurement is not perfect and adds some random noise to the data. The training sample (blue dots) will be used to build the model. The trained models will be validated on the testing sample (red dots). The testing sample is the unobserved data for the model. Hence, the accuracy on the testing sample is a good proof that the model is generalizable.
The First Model – Complete Freedom or No Regularization
Here, response variable, y, is the sine function i.e. sin(x). The X-variables, predictors, are the 15 polynomial terms of x.
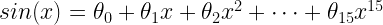
The first model is built without any regularization terms – grandma’s first instruction! This means the model has a complete freedom to choose the θ-parameters without any constraints. This model’s estimated curve is shown with the orange line in this plot.
 The model-fit looks quite good for both train and test data between -4 to +4 range. The model, however, goes nuts on either corner. This erratic behavior could be attributed to fewer blue dots (training data) in these positions. The model has, essentially, tried to perfectly fit every blue dot. This is the reason the MSE for the training sample is very low at 0.02. This perfect fit, however, is not generalizable. Hence, the MSE for the testing sample is close to 2 million (whoops). We need to make the model more generalizable by adding regularization terms.
The model-fit looks quite good for both train and test data between -4 to +4 range. The model, however, goes nuts on either corner. This erratic behavior could be attributed to fewer blue dots (training data) in these positions. The model has, essentially, tried to perfectly fit every blue dot. This is the reason the MSE for the training sample is very low at 0.02. This perfect fit, however, is not generalizable. Hence, the MSE for the testing sample is close to 2 million (whoops). We need to make the model more generalizable by adding regularization terms.
Second Model – Intuitive Regularization Term
Now, let’s add an intuitive regularization term to this model. We know, from the previous article, that for the sine curve the even powers of x (i.e. x2, x4, x6…) have no contribution. In other words, θ2 =0, θ4=0, θ6 =0 and so on. This is a good case for L1 regularization. Remember, Lasso or L1 regularization reduces the θ parameters for useless terms to zero – unlike Ridge regression. This means we will set hyper-parameter alpha to one for this model (α=1).
Moreover, the non-regularized model was performing quite OK for the x range of -4 to 4. Hence, we don’t want to add a very strong regularization term to our model. This means we will keep the value of the second hyper-parameter, lambda, small i.e. λ = 0.0001.
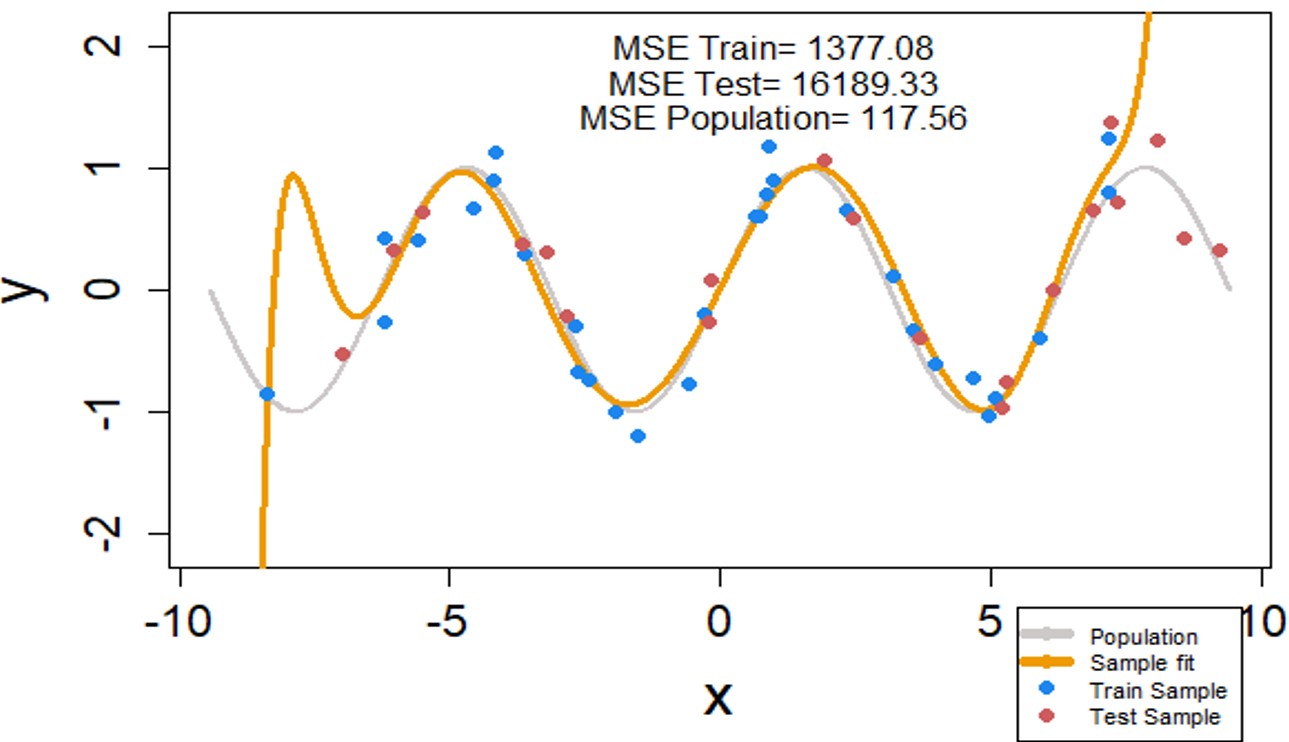
For this regularized model, the MSE for the training data has significantly gone up from 0.02 to 1377. However, the MSE of test data is down by a factor of 100. This model is doing much better on the unobserved test data.
So the model’s accuracy depends on the hyper-parameters: alpha and lambda. But how do we know that we have used the best possible value for lambda and alpha in the loss function? A solution to the problem of identification of optimal values for the hyper-parameters is…
Cross-Validation
Cross-validation is a way to test several combinations of hyper-parameters to identify their optimal values. This method works on the training sample. But wait a minute, we know if we train the model on the entire training data then overfitting is inevitable. There is a clever trick to guard against overfitting i.e. extract a validation sample from the training data. Let’s see how a 5-fold cross validation works.

We have 30 data points in our training data. We will randomly divide these data into 5 groups (5-fold). Each group will have the same size i.e. 6 observations per fold. The models are then trained on 4 folds of data, and the remaining fold is used to test the model. This way you will have 5 models per combination of hyperparameters. The hyper-parameter combination that gives the best model statistics for the testing folds is considered as the optimal. The best model statistics is the lowest value of both mean and standard deviation for MSE (mean standard errors).
Third Model – Explore λ Values with Cross-Validation
We will run a quick and dirty cross-validation model to conclude this article. In the last part of this series, we shall explore cross-validation and hyper-parameter tuning in greater details. In this model, we will keep the alpha fixed to keep things simple i.e. α=1. We will try different values for lambda(λ) to find the best value of λ. We will try one-thousand different values of λ between 10-6 to 1. It turned out that the MSE for λ=0.00448 is the lowest for all the 1000 tried values. The model for this value of lambda is:
 For this third model, the MSE for both training and testing sample is significantly lower than the second model. Our guess for the value of λ was not bad, but cross-validation has done a much better job of finding the best value. This model has essentially lost some level of predictive power in the middle of the plot to achieve a greater accuracy at the corners.
For this third model, the MSE for both training and testing sample is significantly lower than the second model. Our guess for the value of λ was not bad, but cross-validation has done a much better job of finding the best value. This model has essentially lost some level of predictive power in the middle of the plot to achieve a greater accuracy at the corners.
Sign-off Note
As a kid I had no clue that at the fair I was optimizing while being regularized by my grandmother’s instructions. I guess we are training our machines the same way our previous generations trained us.
Wow! What a simple and effective explanation.
Awesome! concepts made easy.