So far we have covered the following topics in this case study example on time series forecasting and ARIMA models:
Part 4: ARIMA model case study example
These topics focused on forecasts using embedded information in the data series. These forecasts are often regarded as good-to-know information and are quite useful for planning purposes. However, they don’t empower organizations with information to change the course of the future.Organizations usually like to know if they could do things better for improved outcomes. They also like to know if their current efforts are generating desired outcomes, and want suggestions for course corrections. These are part of fundamental questions for any organization and require thorough analysis and creativity.
 Keeping with this theme, in this article, we will continue with our case study example and try to answer the question whether the PowerHorse tractors marketing effort is generating added sales revenue. For this, we will use regression with ARIMA errors (ARIMAX) or exogenous variable ARIMA. Before that let’s learn about a useful concept for model selection i.e. Akaike Information Criterion (AIC) through:
Keeping with this theme, in this article, we will continue with our case study example and try to answer the question whether the PowerHorse tractors marketing effort is generating added sales revenue. For this, we will use regression with ARIMA errors (ARIMAX) or exogenous variable ARIMA. Before that let’s learn about a useful concept for model selection i.e. Akaike Information Criterion (AIC) through:
Balancing Acts
Michael Jackson, the king of pop music, is regarded as one of the most famous and truly international artists till date. His net earning from the sales of his music albums had surpassed his peers by a huge margin. Despite this when he died in 2009 he had close to $400 million in debts. Clearly, he could not manage his finances. Elves Presley, another legendary musician, met the same fate when he died. Just before their deaths both these artists were working relentlessly for their stage performances to fight their financial troubles. Clearly, healthy finance is not just about earning well but it is also about managing costs. It’s a fine balancing act between these two parameters as depicted by the following simple equation:
Debt = Cost – Income
For healthy finances, the idea is to keep the debt at the minimum. Model development in data science, like any other endeavor in life, is also about finding the right balance. We will explore the same in the next section while learning about…
Akaike Information Criterion (AIC)
Akaike Information Criterion (AIC) is a mechanism to select the best fit model. AIC has similarities with the debt formula we have seen in the previous section. AIC is an effort to balance the model between goodness-of-fit and number of parameters used in the model. This is similar to the balancing act between income and cost. As a modeler, you care about the maximum goodness of fit (income) with the minimum number of parameters (cost). The formula for AIC is displayed below:
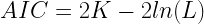
For the given model, L in the above formula is the maximized value of the likelihood function representing goodness-of-fit, and k the number of estimated parameters. Like your debts, you want to keep AIC value at the minimum to choose the best possible model. Bayesian Information Criterion (BIC) is another variant of AIC and is used for the same purpose of best fit model selection. For the best possible model selection, you want to look at AIC, BIC, and AICc (AIC with sample correction) if all these values are minimum for a given model
Regression with ARIMA Errors – Case Study Example
For the last 4 years, PowerHorse tractors is running an expensive marketing and farmer connect program to boost their sales. They are interested in learning the impact of this program on overall sales. As a data science consultant you are helping them with this effort. This is an interesting problem and requires a thorough analysis followed by creative solutions and scientific monitoring mechanism. To begin with you will build models based on regression with ARIMA errors and compare them with the pure play ARIMA model. This analysis will provide some clues towards effectiveness of the marketing program. However, this analysis will not be conclusive for finding shortcomings and enhancements for the program which will require further analysis and creative solutions. The later analysis will become another case study example on YOU CANalytics. The following is the approach you have taken for regression with ARIMA errors. If you want a quick brush up on regression before you jump to regression with ARIMA errors read the following articles
You can find the data for this analysis attached at the end of this article. To begin with, you plot the following scatter plot of same months marketing expense and tractors sales.

This looks promising with quite a high correlation coefficient (ρ > 0.8). However, there is a lurking danger in analyzing non-stationary time series data. Since two uncorrelated series can display high correlation because of time series trend in data. In this case, PowerHorse is a growing company hence both its sales and marketing expenses are on an upward curve. A better way is to find the correlation between stationary data obtained through differencing. The following is the correlation plot for stationary data:
 Ok, so that near perfect correlation has now disappeared though there is still some correlation in this data (ρ = 0.41). Typically, the marketing effort for the previous few months needs to have a good correlation with sales for an effective marketing program. The marketing expense for the last month as displayed below has very little correlation (ρ = 0.17):
Ok, so that near perfect correlation has now disappeared though there is still some correlation in this data (ρ = 0.41). Typically, the marketing effort for the previous few months needs to have a good correlation with sales for an effective marketing program. The marketing expense for the last month as displayed below has very little correlation (ρ = 0.17):

The correlation for the previous quarter also shows non-existent correlation with sales. Now, let’s build a regression model with ARIMA error (ARIMAX) model for the current and previous months.
| Tips to Build Regression with ARIMA Error Models in R |
| In R you could use auto.arima function with xreg to build such models e.g. auto.arima(Tractor_Sales_Data, xreg=Marketing_Expense). Auto.arima function is part of forecast package used in the previous article ARIMA model. |
The following are the results for sales forecast for tractors in a month using marketing expense in regression with ARIMA errors model. Focus on the last part of the results with AIC values.
| Time series: | Tractor Sales with Marketing Expense |
| Best fit Model: ARIMA(0,0,0) | |
| Marketing Expense | |
| Coefficients: | 0.2629 |
| s.e. | 0.0840 |
| log likelihood=-252.38 | |
| AIC=508.76 | BIC=512.33 |
Next, let’s build a pure play forecast without marketing expense as a predictor variable.
| Time series: | Tractor Sales without Marketing Expense | |
| Best fit Model: ARIMA(1,0,0)(0,1,0)[12] | ||
| AR1 | ||
| Coefficients: | -0.3595 | |
| s.e. | 0.1546 | |
| log likelihood=-250.58 | ||
| AIC=323.8 | AICc=324.18 | BIC=326.92 |
Notice AIC, AICc, and BIC values for the plain ARIMA model without marketing expense as predictor variable has lower values of the two models. This indicates that marketing expense is not actually adding value to tractor sales. This is the first indication for the management at PowerHorse to re-evaluate the marketing and farmer connect program. I must point out that evaluation of marketing budgets with a forecasting model like the one we have built is not the best of practices. The best practice is to embed scientific data collection, monitoring, and evaluation mechanism in the design of a marketing program at inception. However, a scientific and well thought out mechanism prior to implementation is often missing in many programs. This is when one could go back in time to use regression with ARIMA error to evaluate effective of marketing programs.
Sign-off Note
Balance is the key to life be it the predator-prey relationship (ecosystem) or planetary motion. The economy also operates to achieve a balance between supply and demand. The perfect balance between our blood pressure and the atmospheric pressure is what saves us from being crushed into pulp or bursting into pieces. Balance is an integral part of a happy life: be it a balance between work and relaxation or personal and social time. May we all achieve this balance to live a happy life.
| Data: Sales and Marketing
R Code: R Code – Exogenous ARIMA model |
Hi Roopam,
I’m interested to know what other measures were available in the data if marketing expenses were not adding value to tractor sales.
Hi Radha,
Sorry for delay in response to your comment I was really tied up for the last few weeks. To answer your question, this problem was specific towards evaluation of effectiveness of marketing budget. However, the same analysis could be extended for overall demand forecasting. For instance, exogenous variable such as crop yield, weather patterns / forecasts, historic market patterns, lending rates, availability of capital etc. could play role in terms of tractors demand. The idea is to create testable hypotheses around your hunches and use the same technique for evaluation. One big challenge with a problem like this is timely availability of data at uniform frequency (i.e. crop yield is generated a couple of times a year vs. monthly sales data). There are creative way to address such challenges.
Hi Roopam,
Can you post the actual data so we can recreate your results?
Hi Tom,
Have attached the data towards the end of the article. I would love to hear about your thoughts and analysis strategy. It will be great if you could write a guest-article on YOU CANalytics with your outlier and dummy variables startegy. Let me know if that works for you.
Cheers
Roopam
Hello Roopam
I finished reading your fifth delivery, that’s fine, but I have some doubts. The ARIMAX model you used is different from that had developed before, you do not have the same terms AR, MA nor is differentiated. Is it because you used the command bestfit R? On the other hand, I tried to replicate what you have developed, but at lower data, I have realized that data marketing expenses are available only for the last four years, the company did not previously have a marketing budget?
thank you
Gabriel.
Yes the models are different since we are using datasets of different time periods. This particular marketing program started just a few years ago as mentioned in the article. This is often the case with analysis in industry where rarely will you find complete data across time-frames.
Hi Roopam,
Could you please also discuss about the exponential smoothing and UCM techniques? I feel it will be very helpful for us.
Roopam ,
You asked Tom to write an article explaining how diagnostic checking using Intervention Detection schemes could be used to improve upon your model. I would be glad to accept your offer. Please let me know how I can do this.
Regards
Dave Reilly
Thanks David for your offer, let me create a guest account for you on YOU CANalytics soon. Will share the details over mail. Look forward to your article.
Regards,
Roopam
Your ma coefficient of 347.4339 in the Transfer Function Model with the ARIMA model of (1,0,1) is outside the unit circle (-1 to 1) .This is probably due to the overspecified ARIMA model ( both ar and ma) when an either an ar or an ma ( probably ar !) might have been appropriate. Another possibility is your estimation procedure. Maximum Likelihood does not constrain the parameters to the invertable region . The “fact” that the AIC/BIC criterion might have lead you to this model reflects the wholesale inadequacy of a procedure that uses a list-based procedure and ignores the possible impact of anomalous data.. Beware of procedures that mindlessly fits all models rather than logically identifying and refining possible models using diagnostic checking incorporating necessity and sufficiency checks.
Thanks Dave, would love to read your complete article about improving this model, and creative ways to think about this problem. Let me know if I could be of any help while you are working on the article.
Caveat: More correctly MLE does not constrain the parameters but some software applications do allow the user to manually set constraints which clearly was not done/implemented with the software you used. Thus two “problems” are at hand ….1) Model Specification Bias and 2) Non-invertible solution .
I am not good at English so much ,but i found it useful and creative, i am doing a predictive data recently,when i difference the data,it plot like,funny,can you give me some advice whether i should continuly difference the data or with a log transformation?
Log transformation is done to make the data stationary about the mean and variance. If your data is stationary while calculating differences, then you need not apply log transformations.
This is what I have understood.
Hope it helps!
i`m confused now as adding an external independent variable using ARIMAX does not take auto correlation(AR and MA are 0) into account.
Also, could you please explain MA works. Its the moving error – taken from previous period but how to get the first instance of it in the series?
I was just wondering if it is possible to get the R code for what you did in this example please ?
Best regards
Hi Roopam
Your juicer analogy does not quite work. Yes ARIMA does require three cycles but presumably with the sugar cane juice each cycle yields some sweet nectar albeit in declining quantities. With ARIMA we squeeze out what is traditionally most sought after: the signal which gives the information we want (trend, seasonality, and non-random error) until we are left with just noise. What your analogy lacks (and virtually every explanation I have seen so far on ARIMA also lacks) is how ARIMA uses the signal components strained out in the first three cycles to make reliable forecasts. All focus is on getting to white noise and then somehow by magic we get reliable forecasting. I need a better explanation as to how trend, seasonality and non-random error are retained in the forecast process not eliminated. Or is it the hidden assumption of ARIMA modeling that white noise is a better predictor of the future than trend, seasonality and non-random error?
Hi Mike,
I suggest you read a bit more about regression analysis. The roots of ARIMA models are in regression where white noise has an important role. In time series modelling without exogenous variables, the logical predictor variables are the previous values of the series and errors. ARIMA in essence is a regression model with these assumed predictor variables. For instance, quarterly seasonality in data can be modelled with this relationship Yt=f(Yt-4). This is part of seasonal ARIMA models. Also to develop intuition about extraction of trend by differencing, simulate different datasets and use differencing to see how it works. I find simulation a good way to develop intuition about complicated concepts in statistics and machine learning.
Roopam
Thanks for taking the time to answer my post.
I have a fairly good idea about how non-ARIMA simple and multiple regression works. This is my understanding and feel free to correct me:
1. Using a least square criteria we can compute an equation with one or more independent variables and an error term. The least square computation assures us that there is no other equation that fits the observed Y values better. The derived regression equation assures us that there is no other model in which the squared differences between the Y values predicted by the equation and the previously observed Y values are smaller.
2. We can, using an easily computed measure, “r2” get a sense of how much of the variation between fitted Y and observed Y is due to the coefficients of the independent variables and how much is due to the error term. In other words we have a measure that tells us how well our regression model explains the variation in observed Y.
3. We also can also perform statistical tests of significance on the coefficients of the regression equation. We can assign probabilities that any particular coefficient is not zero. We can compute confidence intervals for the values of coefficients.
4. We can analyze the residuals (or error terms) to determine if our regression equation is mis-specified. A non-random pattern of residuals can tell us if we are missing an exogenous variable or whether a non-linear model would be better than a linear model. We can, if need be, transform the original data in any number of ways to find a linear model.
5. We can combine nominal, ordinal and continuous variables in the same model.
6. While we are well warned that correlation is not causation many of the tools of regression serve as input for SEQ modeling that seeks to tease out causation.
Compared to OLS regression ARIMA is literally an un-intuitive black box procedure. I have spent literally hours and hours searching the web to find out the rationale for ARIMA and have yet to find it. Your juicer model raised my hopes but in the end failed. Because the end result of the cycles is white noise as opposed to an equation making use of trend and non-random error the process seems almost insane. Perhaps all that is missing is some description of how by multiple passes at the data via differencing we arrive at an equation that best captures trend.
I know that there is an analogue between a least square criterion for finding the best fit model in OLS and MLE in ARIMA but this needs to be way better fleshed out. But I can easily visualize the least square criterion but what of MLE?
You are clearly a very smart and imaginative fellow and I think if you can capture how MLE works then maybe, maybe you can make ARIMA methodology more intuitively tractable.
Thanks so much for your efforts.
Mike
Its not ARIMA errors. Its just ARIMA.. the MA component incorporates the errors from the previous periods.
Hi, If data we are taking which is steadily increasing then it is giving prediction but if data is not increasing steadily but it is changing at any time then it is not showing proper prediction in graph. SO please give me solution for other than time series data for ARIMA
Nice article on time series! I would like to know how to do vice versa (when we know :: AR & MA and reg. Co-effi in advance) & to write a model in R ( I guess forecast package may help; but yet to get success on it) ; pl help;
In matlab I am doing it as follows:
model = regARIMA(‘Intercept’,0,’AR’, {0.5 -0.8}, ‘MA’, -0.5, ‘Beta’,[0.1; -0.2], ‘Variance’, 0.1, ‘D’, 1);
With a package that includes regression and basic time series procedures, it’s relatively easy to use an iterative procedure to determine adjusted regression coefficient estimates and their standard errors.